
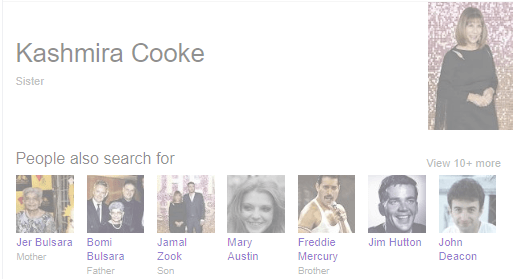
When researching how the KG was being updated, it initially took me a long time to find entities that were anything except Wikipedia listings. It turns out, though, that Google has a lot of data that it does not initially reveal in the knowledge graph answer box.
Google’s knowledge graph extrapolates insights gleaned from its data set. Here is an example:
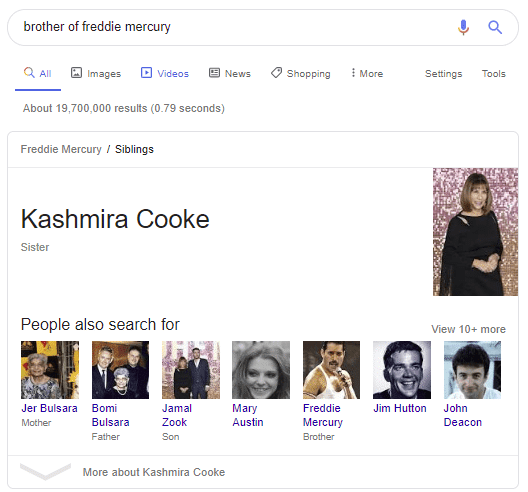
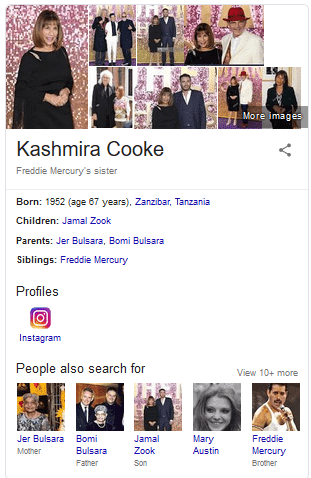
Google made two leaps here. The first was in what I searched for. I searched for “brother” and Google returned a sister! Google knows that “brother”, “Sister” and “siblings are semantically so close that Google made the substitution for me (and didn’t even tell me that it had). The second leap is that Google has provided details on a person without their own Wikipedia page.
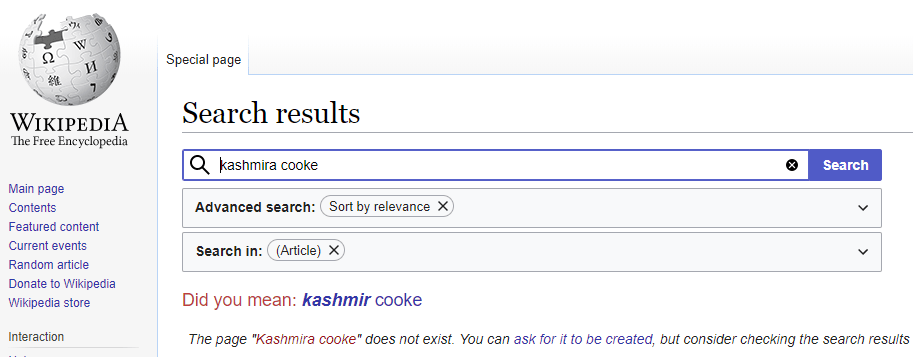
In fact, there is no specific entity for Kasmira Cooke anywhere in the Wikimedia set of sites, if we use “Wikidata.org” as a measure:
How did Google get to this level of confidence? Google uses content to add to existing entries and in the process, creates new relationships. each “triple” as described in an earlier section, creates two entities. So in this case, Google felt it could trust the content on Wikipedia which gives several triples in just this section:

Now Google knows:
- Freddie Mercury (is the brother of) Kasmira Bulsara
- KashmiraBulsara (is a type of) Person
- KashmiraBulsara (is the same as) Kasmira Cooke
In fact, Google can then carry on collecting information about the new entity. Put “Kasmira Cooke” into Google and you get a pretty solid looking knowledge box.
What this teaches SEOs
You do not NEED to have a Wikipedia page to get your own entity in Google’s Knowledge Graph. Even so, it very much helps to be related (in this case quite literally) to an entity existing in Wikipedia. Have a good think about the entity you would LIKE to get listed in Google’s knowledge graph. Does it have any close relationships with any listings in Wikipedia? Does the person running that entity have a famous brother/sister/father/mother? If so, that person might get listed in Wikipedia as related to an existing entity. From there, they have their own entity. After this, you can possibly use schema to help Google understand that this entity runs the entity you wish to get listed.
Hire a Chair / Patron
Not all of us have the luxury of a famous brother or sister. But Princess Anne has nine pages of charities that she supports. These allow Google to make the connection. It does not in any way GUARANTEE it, though. Leuchie Forever Fund is a charity supported by Princess Royal, but as of the writing date, this charity did not have an entity, but it offers a potential path for the enterprising SEO to develop.
Who says that the Old School Tie network is dying out in the age of automation?
Start with a Unique Word to Brand your Entity
Google would have had a lot more difficulty in making these relationships if Freddie Mercury was not a unique name and if his surname had not been “Bulsara”. Uniqueness helps the KG reach levels of confidence faster. I am not suggesting a change of name will guarantee success, but it might be a consideration if you are just starting out and have not yet settled on a strategy.
Google is an agnostic White Man
This might be a little contentious, but “brother” and “sister” both have different meanings in black and religious communities. Google has connected these words so closely with the word “siblings” that its algorithm may have become closed to other interpretations of these words. This may emanate from the types of people involved in curating the initial seed set. This bias is a recognized problem in the building of Knowledge graphs.
There are also other databases that google considers beyond Wikipedia… let’s look at a few approaches to getting into these…
Leave a Reply
Want to join the discussion?Feel free to contribute!