Semantic Search Guide
How to do an Internal Link Audit for SEO
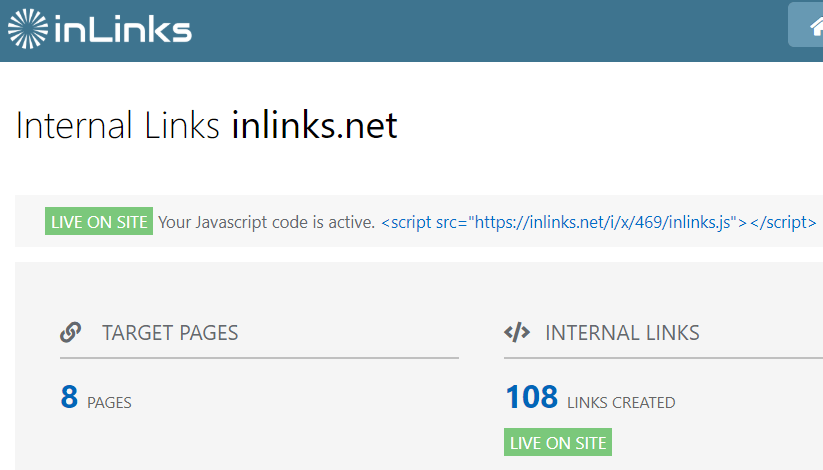
A well-crafted internal link structure improves your chances of your content being seen. At the


A well-crafted internal link structure improves your chances of your content being seen. At the
You can define your own entities on your own web pages. When a search engine
Creating Digital Assets Whether you have decided that your strategy is to be the entity,
This is much harder than it sounds, mostly because businesses do not entirely agree with
Being the Entity If you are a business or organisation, then you ARE an entity.
Become an entity or an expert on an entity Your first strategic decision is whether

Getting a Wikipedia entry is fraught with dangers. Inlinks has chosen not to list a
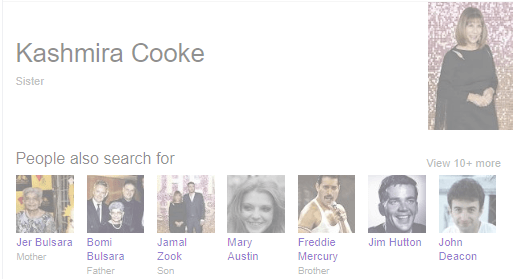
Google’s Knowledge Graph is built upon Entities, primarily – but not exclusively – derived from

Know what is an Entity (and what isn’t ) Just as you can type in
This is not the first book or content you should ever read on SEO. There
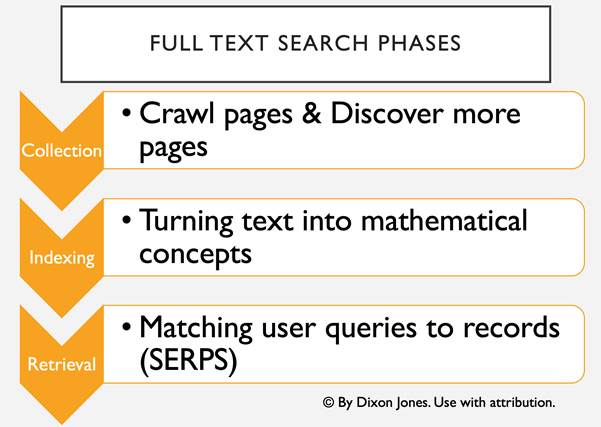
Summary: Modern Search Engines can derive insights across multiple documents instantly. Cataloguing systems over the
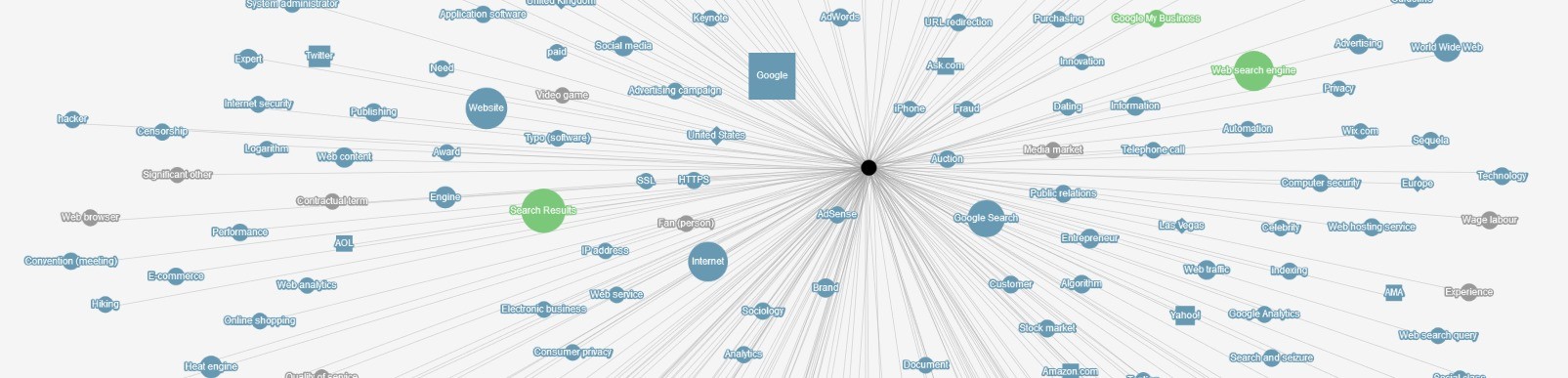
What (exactly) IS Google Knowledge Graph? Google Knowledge Graph is technically a knowledge base containing
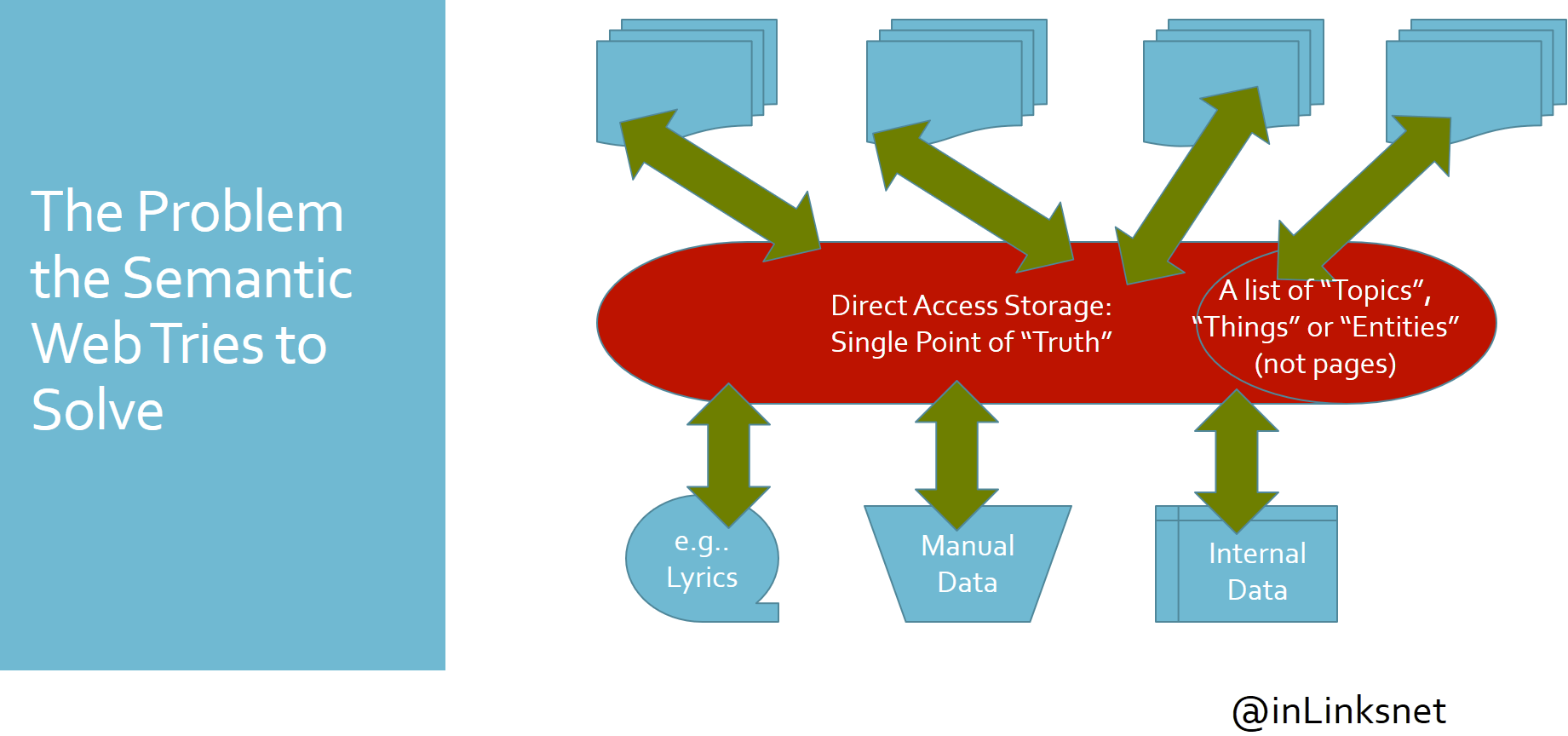
This Semantic Search Guide shows SEOs how Information Retrieval systems have moved from a web


