
Entity-based SEO is a new field, full of possibilities, but where solid approaches still need to be developed. This includes the theory, the techniques and the tools for using entities to optimize your site.
For a start let’s break down confusion in understanding what SEO entities really are. Many articles have already been published on entities and their role in the evolution of web indexing. For many professionals, however, it remains difficult to understand. Why do entities make it possible to set up a sustainable SEO strategy and how they can be used to improve website performance?
This guide aims to show why you need entities to make your SEO effort more effective and how to use entities to improve on-page SEO, consolidate a site’s architecture and improve your traffic acquisition strategies.
What you will find in this guide:
1. What is an SEO entity?
SEO stands for Search Engine Optimization, the practice of increasing the quantity and quality of traffic to your website through organic search engine results.
From the start, SEOs have mainly focused on keywords to increase traffic.
Entity-based SEO is all about focusing on entities rather than keywords. Put it like that it’s simple, but it requires a fundamental change of mindset.
What is a keyword?
In SEO, a keyword is made up of one or more words entered by a user in a search engine such as Google or Bing.
When search engines began, the notion of keywords has formed the basis of natural referencing strategies, with the aim of ensuring the visibility of a page in search engine results, for one or more specific phrases.
Keywords have two basic characteristics:
- They carry ambiguity. A keyword can refer to several very different subjects. The keyword “Cookie” can, for example, refer to an edible biscuit or to the information sent by a Web server when a page loads.
- A keyword is most of the time specific to a language. The keyword “machine à laver” in French corresponds to “washing machine” in English or “lavadora” in Spanish.
What is an entity?
In general, an entity (or named entity to be more precise) designates a single, well-defined thing or concept which can be linked to a knowledge graph.
Unlike a keyword, which is ultimately just a collection of letters specific to a language, an entity carries meaning and is independent of the language and of the synonymous keywords that designate it.
More precisely, in the SEO world, an entity concerns any subject that can be linked to the knowledge graphs of search engines, such as the Google Knowledge Graph.
We know that Wikipedia acted as a primary trusted seed set for the Knowledge Graph. For simplicity, we can call an Entity any subject that can be attached to a Wikipedia article page, (other than disambiguation or a category pages).
For example :
| Entity type | Keyword synonym | Corresponding entity |
| Person | Trump | Donald trump |
| Location | Paris | Paris, France |
| Organization | Alphabet | Alphabet Inc |
| Event | CES | Consumer Electronics Show |
| Concept / Thing | SEO | Search Engine Optimization |
To optimize on-page and on-site SEO, we should be focussing on which underlying entities to use to help a search engine understand the enderlying meaning of the content.
Note: there are other types of entities, such as you, your brand, your company, which while not having Wikipedia pages, can be linked to other Knowledge Graphs (such as Google MyBusiness or Linkedin). However, optimizing these entities will only improve your reputation, not your SEO.
Frequently encountered mistakes regarding entities
There are a lot of errors on the web about entities in SEO. It seems essential to us to remove any ambiguity or confusion here.
Errors encountered in SEO literature
Take, for example, this Search Engine Watch article about optimizing content using entities.
The author suggests that “player”, “best basketball shoes” and “basketball” are entities discovered by Google during the analysis of a text on basketball.

What are the mistakes made here? Best Basketball Shoes certainly does not refer to an entity because there is no Wikipedia page on the subject.
Basketball shoes is also not an entity. This is a synonymous keyword referring to the Entity Sneakers.
Even the word Nike refers to the entity Nike, Inc. This entity was correctly detected by Google NLP, which creates a synonym: the word “Nike” but links to the Wikipedia page of the entity Nike, Inc.
What to remember from this:
Google only lists keywords in its natural language API interface. The entities correspond to the Wikipedia links associated with each word.
Other errors encountered
The example Wikipedia gives on its page regarding named entities is also confusing.
Here is a quote on the Wikipedia page (as of 12 Jan 2021):
…Consider the sentence Trump is the president of the United States. Both Trump and the United States are named entities since they refer to specific objects (Donald Trump and United States). However, president is not a named entity since it can be used to refer to many different objects in different worlds”
Excerpt from Wikipedia (contested)
This claim is wrong for the following reasons:
- Trump is a keyword synonymous with the Donald Trump entity (and therefore the word Trump is not in itself an entity, it can also refer, depending on the context, to the Trump entity (card game) in English, or Trump in French)
- Likewise, President is a keyword synonymous with the entity President of the United States (identified in the Google Knowledge Graph by the ID / m /060d2), which can be easily disambiguated by analyzing the context of the sentence, especially since this entity is exactly named in the sentence above.
The sentence given as an example by Wikipedia ultimately referred to 3 entities: Donald Trump, President of the United States and United States.
Terminology used by Google: Entities, Topics or both?
As we will see below, Google uses entities in most of its web services (Google Search, Google Discover, Google News and Google Trends in particular).
On the other hand, Google hardly ever uses the term Entity, preferring the term Subject in French or Topic in English, as shown in the screenshots below. All of the “Topics” mentioned are actually Entities.
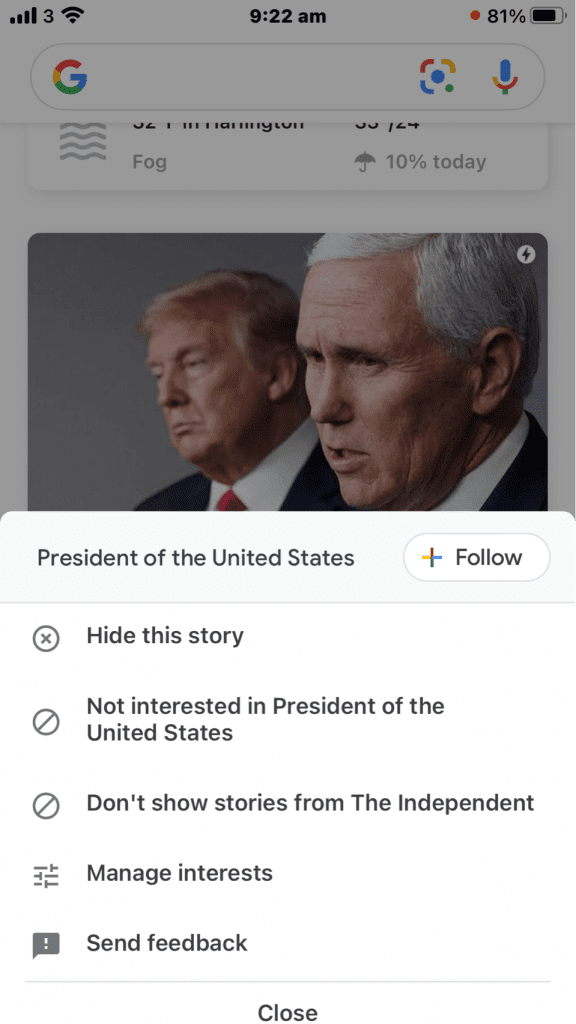
So it’s important to be wary of the way Google names things (but you probably already know that).
2. How does Google use entities?
Why Google uses entities
Before answering the question of “How”, it is interesting to first question the “Why”. Why are entities today at the heart of Google’s algorithms and services and why are they now tending to replace keywords bit by bit?
One reason is obvious. If Google uses entities, it is because these entities make it possible to connect all the world’s information together, regardless of the language. Entities make it possible to understand the meaning of this information as well as the centres of interest of its users.
Google uses entities because these entities make it possible to connect all the world’s information together, regardless of the language. Entities make it possible to understand the meaning of this information as well as the centres of interest of its users.
By detecting the entities contained in web pages, Google will be able to link two sites talking about the same thing in different languages.
In the example opposite, Google offers, via Discover, an article in English to a French user interested in the “Search engine optimization” entity (and who has previously consulted English sites on the same topic).
We will see that personalization via entities goes far beyond Google Discover.
What Google services use entities?
In its 2018 article “ Helping you along your Search journeys ” Google already claimed to detect and index the entities contained in all web pages published on the Web, with many key applications.
If we had to summarize all of these applications, we could say that Google uses entities to interpret and categorize web pages, establish relationships between entities (and therefore between web pages), and deliver better answers to questions for Web users.
The Knowledge Graph
As reported by Google, the Knowledge Graph is used by Google Search to help users discover information faster and easier. This Knowledge Graph contains most of the real-world entities such as people, places and objects and is refreshed by a Wikipedia dump every night.
The use of the Knowledge Graph essentially allows Google to:
- Present knowledge panels for the entities searched by Internet users,
- Refine the results of its other services based on users’ interests.
Google search
The use of entities allows Google to personalize the results delivered by its search engine, based on the interests of its users and its search history.
Without second-guessing the details of updates to Google’s algorithm, many have been focussed on entities:
- Google Hummingbird: With this update, Google transformed the way it handled internet users’ queries by moving from an approach based on keywords (strings) to an approach based on entities (things).
- Google Rankbrain: RankBrain allows Google to better respond to queries that it has never encountered before. This is achieved using entities and an artificial intelligence layer.
- Google BERT: This setting uses Natural Language Processing (NLP) to understand search queries, interpret text on web pages, and thus identify entities and relationships that connect them.
Thanks to these successive improvements, Google is now able to reformulate Internet users’ requests and, it is probable, also reformulate the content of Web pages.
The search suggestions provided by Google also increasingly include entity suggestions.
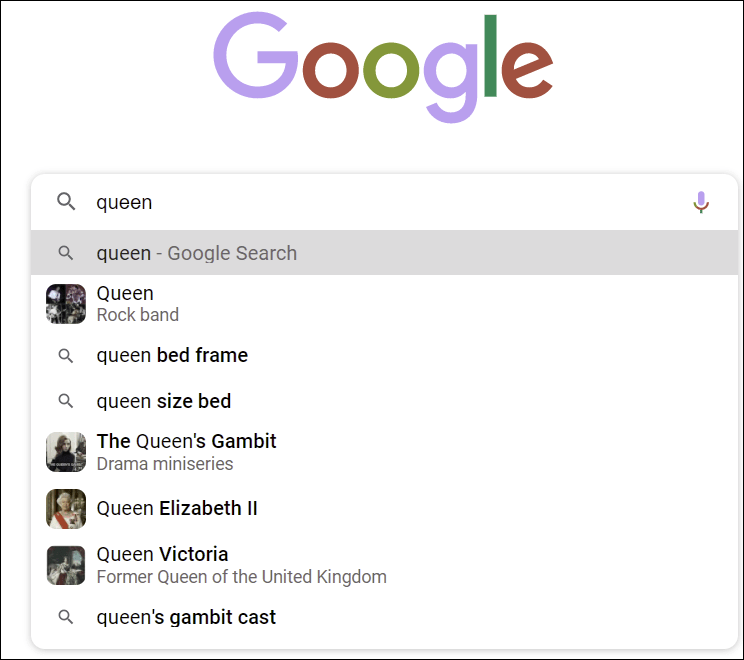
By searching for “queen” without using the suggestion, we get a mix of ideas in the results, but using the suggestion box we can obtain a list of results which is quite surprising because it contains no errors (no suggestion of monarchs or films, for example), which clearly shows that Google delivers search results based only on entities and no longer just on keywords.
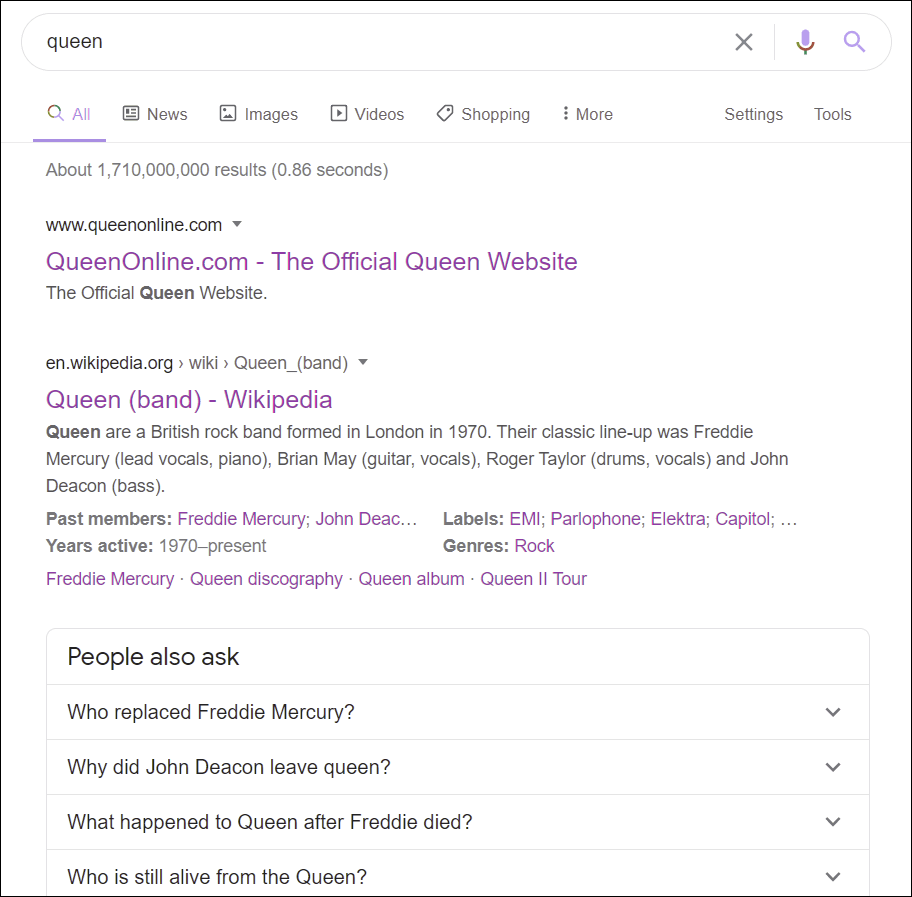
Google Discover
As seen above, all the results offered by Google Discover are based on the interests of a user, ie the entities contained in the web pages they use. From these pages, Google builds what it calls the “ Topic Layer ” (read Entity for Topic), ie the graph of the interests of each user.
Whenever a new article is published on the web that includes one of these areas of interest, Google may suggest it to the corresponding user in Google Discover.
Google Trends
Google offers two types of research on its trends tool:
- Searching by “search term”, ie by keyword
- Search by “subject”, ie by the entity.
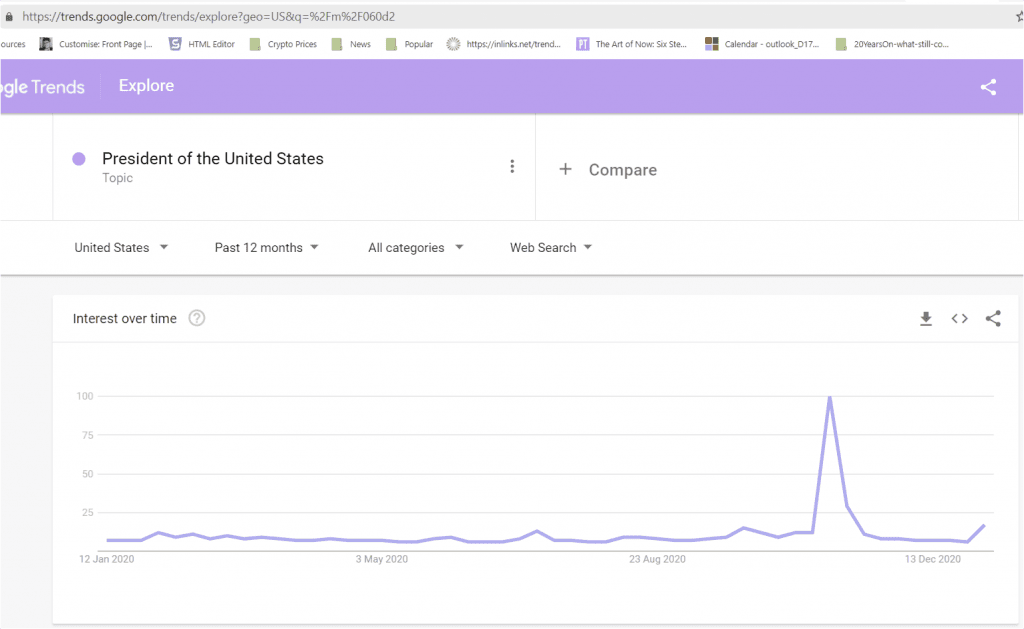
Here is the example of a trend for the entity /m/060d2 already seen above and accessible at the URL https://trends.google.com/trends/explore?geo=US&q=%2Fm%2F060d2
How does Google detect entities?
The studies that we carried out with InLinks, and in particular through Industry reports, show that Google only detects on average 20% of the entities present in a text.
This result is achieved using exclusively the Google NLP API.
However, our studies show that in many cases Google’s API does not directly detect the primary entity in the articles it offers on Google Discover.
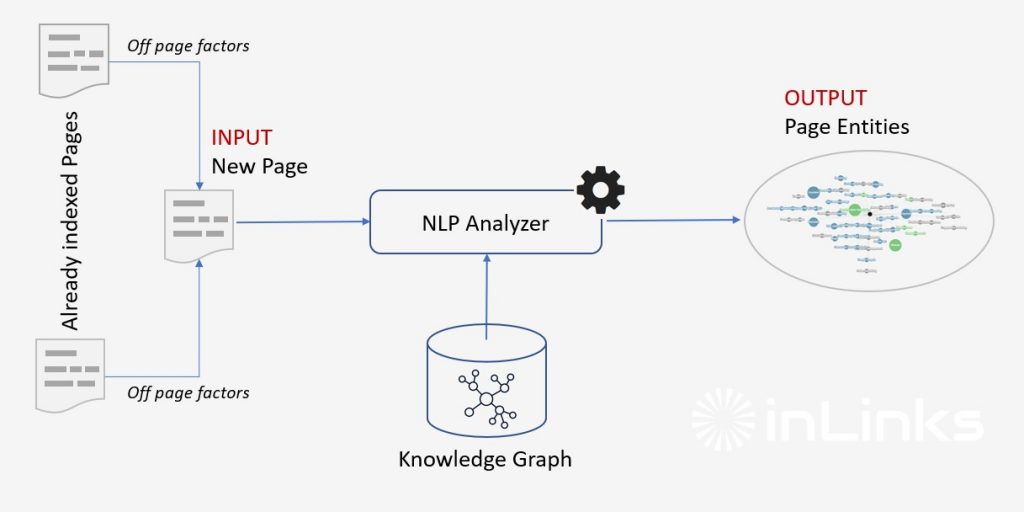
It is, therefore, reasonable to think that Google uses different methods to determine the entities present on a page:
- An NLP algorithm, similar to its API (their API detects almost 100% of people, places and organizations, but very few concepts/things),
- Off-page factors, such as the entities detected in the other pages of the site (acting as contextual entities and allowing an additional step of disambiguation)
- On-page factors such as Schema.org markup to explicitly specify the entities present in the page



Great read, thanks for pulling all the things together into one article.
Great read! I’m finding it very interesting how SEOs use entities to optimize pages. Would definitely like to see more case studies of the “how”, with results.
Thanks. Here are some Case Stidies for you. https://inlinks.com/category/case-studies/
The discussion is so complete, it makes me dizzy to read it
This is the perfect reminder at the perfect time about Entities and SEO. I had toyed with the NLP demo a while back, and found it helpful to focus my content in bite-sized portions. I drifted away, but thanks to you, I’m refocused. Thank you sir!
That’s great news! 🙂 Thanks.
Awesome article, these days i am too curious to learn entity seo. Still finding more detailed guide on how to implement it.
Thank you for the thorough analysis
That’s great. Thanks a lot.
So far, I thought SEO was just a game of keywords, but it turns out that there are so many paradigms that I have to understand from just playing keywords to optimize my website. and I will make this article as a reference in more depth in studying SEO. thank you for the light
This is the best article on the use of entities in SEO. Thank you very much, Dixon, for writing such an informative article. It was extremely beneficial to me.
Thanks for article, Dixon. Quick question, what’s the difference between entities and word embeddings and how would google use both in search simultaneously? Thanks
I don’t understand the phrase “word embeddings”, so apologies if my response misses the mark. If you mean “Injecting keywords into an article”, I think the main difference is in whether you are simply trying ti trick Google into thinking you know about a topic and actually adding value around a topic. Of course, Entities are also just words… but my point here is that Google is trying to underdstand the Entities… whether you are injecting words or not. The word is (in Google’s world) just a descriptor for an underlying thing/person/organization/Event etc and many words may mean the same thing.
Great blog Dixon. Detailed analysis. I have been focusing more on entity-based SEO and used your tool recently and got great results.
That’s the kind of comment I like to see! 🙂
Oh gosh, Dixon, every time I read something by you, I understand a little more. But this article really summed it up and I think I understand it enough to explain to my clients. Finally! Thank you.
Thank you for clarifying the essence of SEO. Interesting approach!
Thanx !! My site follows all above advice !!
Thanks for sharing the entity-based SEO Blog.
Wow, it’s an informative post. Thank you for sharing such a great blog.
it’s an informative post. Thank you for sharing such a great blog.
Hi Sir
I have my personal website and I’m trying my best to give an “entity home” to my personal name,
I have the page with my name, link my all profile with the page added schema. But still, Google is unable to create my entity on the web. On the search, Google shows my Twitter and GMB listing.
how can I help my entity with it if you have any idea, I will love to know.
Hi Krishna,
Thank you for reading. Putting schema on your web page will only help Google if there are other pages (usually not in your control) helping to reinforce the message that your page is the authoritative home for you. Indeed, Google will be unlikely to consider you as a person of note at all, until there are enough citations and mentions of you elsewhere online. A person that has done a lot of work on this idea is “Jason Barnard”, who runs Kalicube.pro. He recommends you continually reinforcing the message of where your identity home lies, by making every refernce to you on the Internet that you can find, link through to your home page. This might include sites like LinkedIn and Cruchbase, for example. Site outside your control are even better, though. It’s not easy.
Thank you, Dixon
I also, talk about this to Jason Barnard.
he helps me a lot by adding my website to his tool.
Any recommendations that help me/anyone with citations?
I’m already trying to work on all the sources Jason talks about. (Linkedin, CrunchBase… )
Jason’s list is awesome! You can also try his tool, Kalicube.pro. I did and it has helped me to disambiguate.
The biggest challengs, though, is to become “famous” enough to be seen as an entity. It is often easier to develop around topics that are “things” rather than “people”, in part because Wikipedia and others have legal responsibilities when storing information about people. This means there needs to be compelling evidence that the persin is in the public eye.
Thank you Dixon for this helpful guide
This is a great guide, I am finally able to wrap my head around this entity thing.
Thanks!
Written in a well-versed manner. Thanks for Sharing.
knowledgeable content
Great blog about SEO entities, thank you for sharing this informative article with us.
knowledgeable conternt
Good article to enhance your seo skills.
Inlinks was heavily used as part of my recent SEO campaign, you can check out my case study here tomrileyseo.co.uk/financial-advisor-seo-case-study
Hey Dixon. Great read. Although I couldn’t find a free simple tool which helps in finding related entities and creating topics out of them. Your input on this would be highly appreciated
Thanks. Inlinks.net is free for one content brief per month, or you can analyze one page at a time on our hime page without logging in. IBM Watson also has a free entity extraction tool, but in test. ours is stronger (for seo)
Thanks for the very helpful content. I have a question.
If I’m a non-celebrity and I have a personal blog, ngocanhblog.com, how does Google identify me as an entity and not a virtual person?
Google looks at multiple databases, but only triggers you as an entity when there is a body of evidence, from a range of sources. Jason Barnard at Kalicube maintains a list of datasources that he has seen citing in Knowledge Panels. You can try there to get noticed, But it is not easy. Writing a book helped me.
Thank you for clarifying the essence of SEO. Interesting approach!
Hi Dixon,
I’ve been recently expanding my knowledges on nested schemas. The research has led me to the this article, which I have read in the past.
My question is on nested schema, do you think there should be, or is, a limit to how many schema types and nested elements present withing a JSON LD script tag?
For example a GYM has multiple classes and activies for a single location. Would there be any drawbacks or risks assocciated with dymanically populating the JSON LD with the full list of activities and classes per gym location?
I know it is a little off topic from this post, but it related to entity SEO.
Thanks,
Chris
Hi Chris,
I have seen some incredibly long complicated schema in my time. That does not seem to be a risk, as long as it doesn’t cause page bloat. BUT… I think it helps if you think about schema being a tool to DISAMBIGUTE meaning, (rather than optimize content). In other words, the more schema you add, imaging that it could reduce the number of relevent viewers, but increase their ability to convert. So… if the Gym has 20 courses at the same gym, every week, then if you nested all the courses on one page, you are limiting yourself to an audience of people interested in reviewing the entire course list, but NOT people interested in a particular activity at the gym. A search engine might be happy to extract the salient details form that one page, but I would still have a page for (say) the Swimming lessons and n=another one for (Say) Pilates.
As with so much about schema, it is more about how each crawler / engine decodes the schema than anything else. Is it better to write a history book grouped into Eras, or countries or event types? The truth is, you should write it in the way your audience is most happy to consume it.
That’s probably as clear as mud… but it is how I see it.
thanks for helpful information about SEO
Thanks, this was the best explained article I read about entities. I did not know anything about Google’s problem in identifying entities within a text. Now, I am more convinced of using JSON-ld structured data to feed google.
I am reading tons of articles on the topic of Entity SEO. Thank you for the great piece of content. It is really very helpful as you explained things in a simple and easy way, anyone can understand.
I am glad it is helpful! Thank you for the feedback, Adil.
Thanks for sharing this information sir…. wish you all the best
Great explanation. For a long time I think it’s time to change the way I approach SEO.
Thank you for sharing a very useful insights about Entity Based SEO. I’m trying to implement it on our eCommerce website chic. It is not very much easy to implement it on eCommerce website as we can easily implement it on blogs.
I try to implement on the product page because on the Category page we do not have any content. We have a blog section on the website where I am trying to add but our main focus is to rank the category pages.
One problem with your approach of focussing on each product page, instead of category pages is that you are working at a very granular level. If you use WordPress, there are plugins (and themes) that let you add content at the category level. There are likely better topic/entity associations at this level and the blog content can link more readily to the category pages.
This is really amazing blog.
I really liked your blog!
Thank you for sharing this amazing post
I am owner of a Electrician business and see on the fb for semantic SEO and entity based SEO and search on google and find this one article it’s really help me to understand, thanks,
It is really a very helpful article on Entity SEO. I was looking for a complete guide on this topic as this is on of the hottest topic discussing between SEO’s. I believe this is the future of SEO as well. We are going away from the traditional SEO now.
Leave a Reply
Want to join the discussion?Feel free to contribute!