(Note: This article is the second part of our guide on using entities in SEO. We advise you to read the first part if you are not yet familiar with the concept of entities in SEO.)
Why is Entity Indexing essential to your SEO Strategy?
Any site owner or SEO expert knows the importance of indexing pages by search engines. But indexing a site’s URLs is only the first step. It has now become essential to check how Google interprets the content on these pages.
In the previous part of this guide, we saw that entities have become a central element of Google’s indexing strategy: each page indexed via the Google bot is then analyzed to extract and index the entities present in the text.
The indexing of entities offers many advantages to Google:
- to understand the meaning of the content published on a page,
- to establish connections between pages,
- to understand the requests of its users and reformulate them if necessary
- to map areas of interest to improve search results and content suggestions.
Google now uses entities in most of its services. So it is fundamental to know how Google indexes the entities of a website and to be able to improve this indexing if it proves to be insufficient.
How can you Measure the Indexing Status of the Entities on your site?
In order to be able to measure the indexing status of the entities of a site, you need two tools:
- Google’s natural language analysis API (available here )
- a reference API, allowing identification of all the entities present in a text.
(You can also use an all in one tool like InLinks)
Google’s API, has some interesting interesting characteristics to be aware of:
- This API is particularly powerful for detecting people, companies, places and points of interest that can be found in a text. For these types of entities, its detection rate is close to 100%. The API is also good at detecting certain types of products, such as car models or movies and TV shows.
- However, this API encounters difficulties in correctly detecting entities related to objects and concepts, expressed in the form of common names (see below)
- We also know from Google that the API is based on the same technology that is used in its search algorithm
Google NLP API Performance Overview
InLinks regularly publishes research reports on Google’s ability to detect entities. Here is the summary:
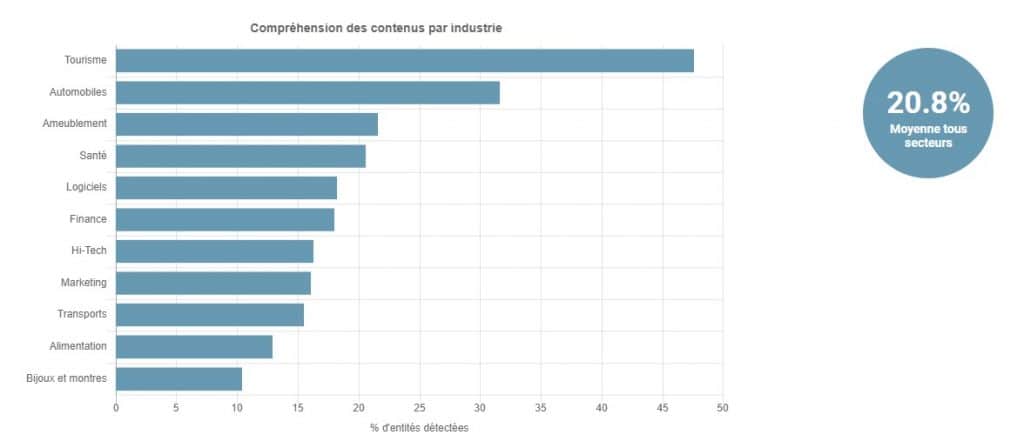
Apart from the tourism sector, for which the API displays a detection rate close to 50% (which is explained by the large number of places and points of interest present in the texts), we note that, for the most part of the sectors of activity analyzed, the detection rate is below the 25% threshold, with an average for all sectors of 20.8%.
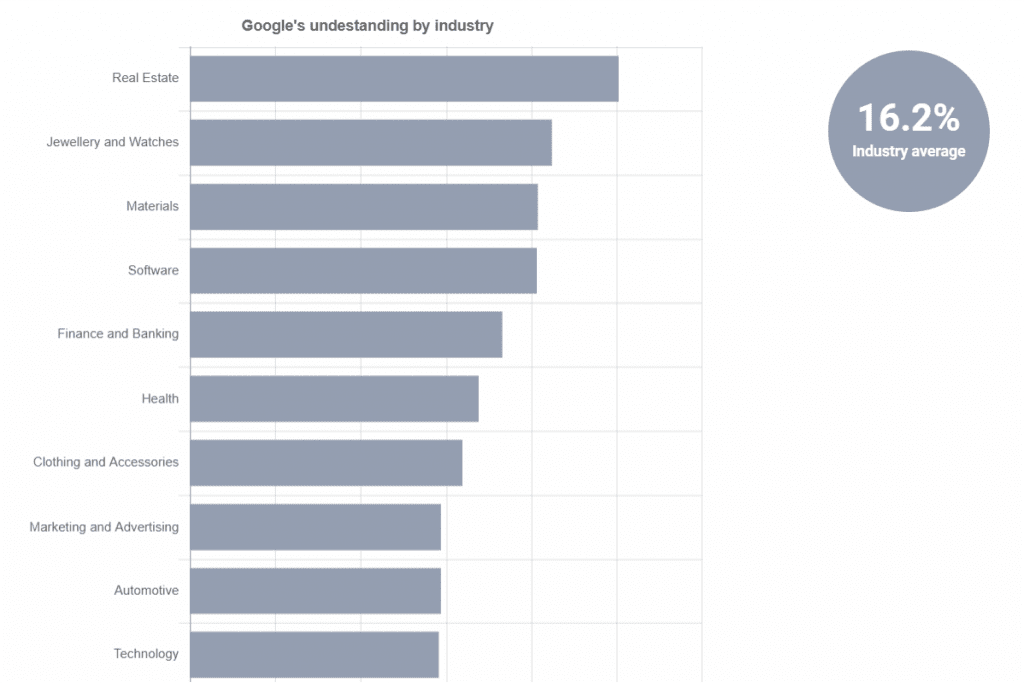
Analysis in English speaking markets has led to an even lower overall detection, although no analysis has been done in English in the Tourism sector, with only Real Estate reaching a 25% threshold.
Now let’s get to the heart of the matter: indexing entities at a page level, then at a site level.
Auditing Indexed Entities on a Page
To know which entities have been detected by Google on a page and which entities have not, we will use the analysis tool directly available on the InLinks home page. This tool compares the results of the Google API with those returned by the API of InLinks.
The example below analyzed the content of the homepage of a well-known SEO software.
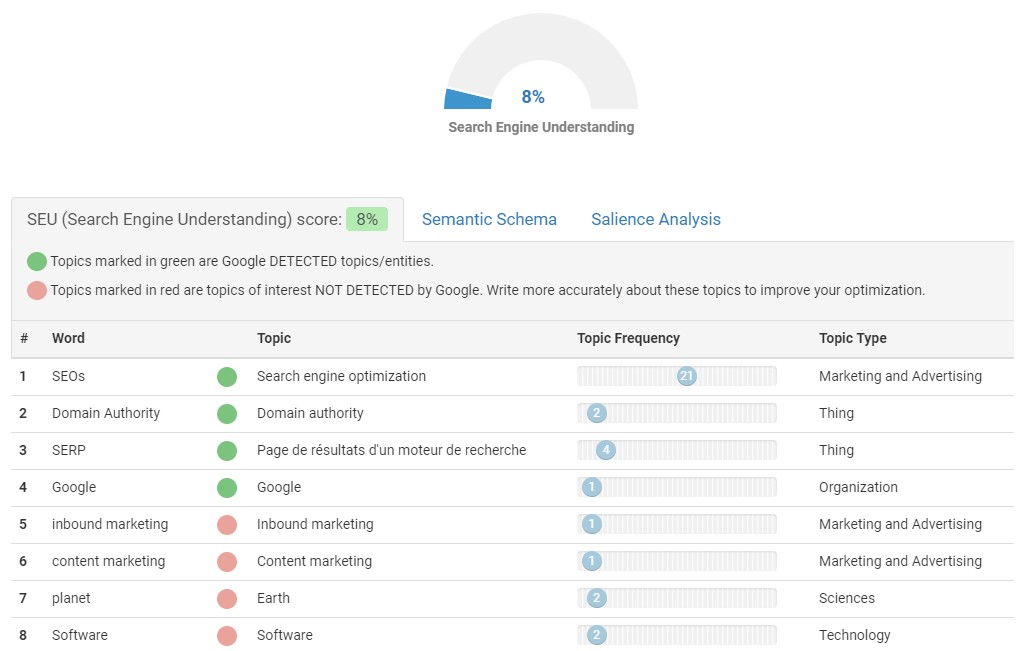
At first glance, the 4 entities detected by Google are quite satisfactory. However, several important entities were not detected, including:
- Software
- Content Marketing
- Inbound marketing
- as well as Keyword research (displayed further down in the results list)
These entities are important because they make it possible either to characterize the product offered on the site (Software), or to highlight the use cases of the software.
So the indexing of the entities on this page is insufficient and needs to be reinforced.
As explained in the first part of the guide, we know that Google also uses off-page factors for indexing entities. It is therefore important to know if these missing entities were detected at the global level of the site.
Audit indexed entities at the site level
By repeating the same operation on the main pages of the site (pages generating the most traffic or strategically important pages in terms of income generation), the compilation of the results allows to obtain an overview of the indexed and non-indexed entities at the level of the site.
Here is the result of this analysis, carried out on the first 130 pages generating traffic of the same site as before. Entities detected by Google are in green text.
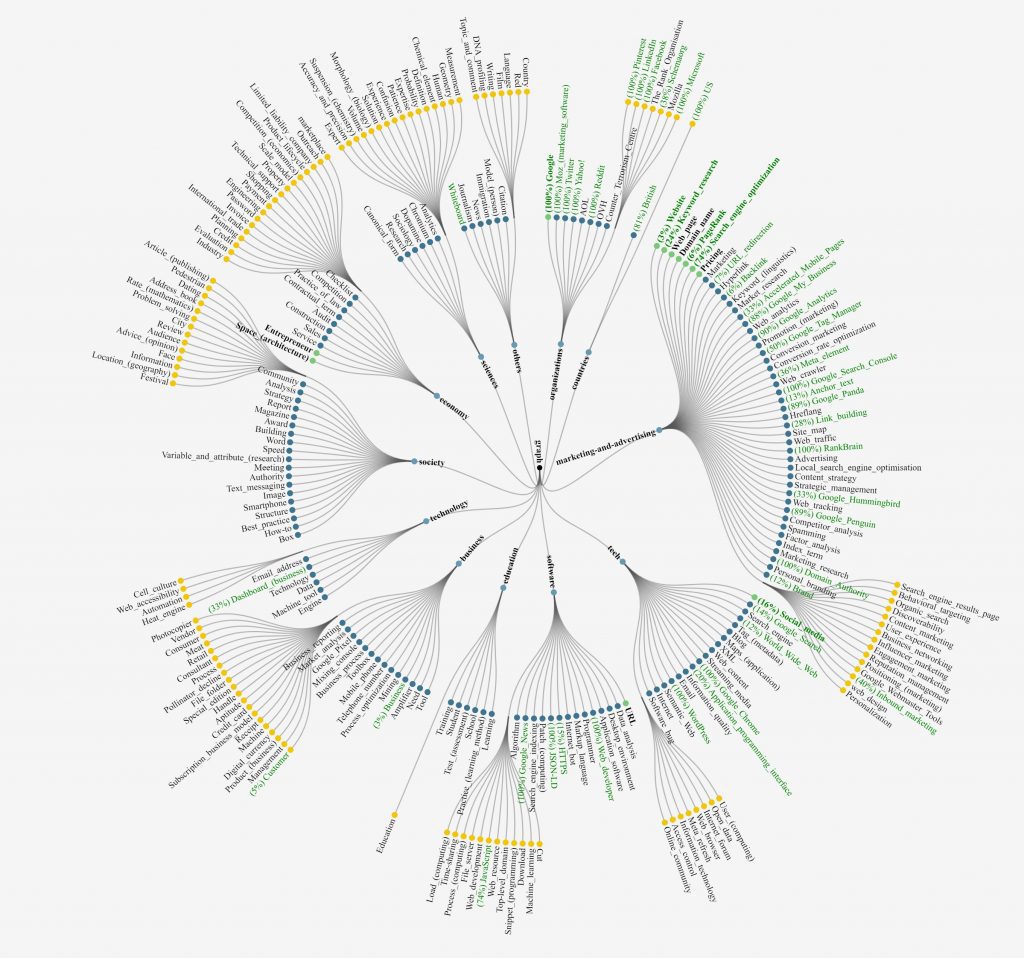
By analyzing the results, we can see that the Content Marketing and Software entities were not detected at the site level. It is therefore necessary to improve the indexing of these two entities.
On the other hand, some important entities are also not detected. This is particularly the case with Competitor Analysis or Local Search Engine Optimization entities , which represent use cases for this software. Here again, this lack of detection requires the implementation of corrective actions.
How can we improve the way Google detects entities?
To improve the detection of entities by Google, we essentially have 3 possibilities:
- the way the text is written
- Using Mark-up language to highlight the entities (schema.org)
- off-page factors (Having entities indexed on other pages of the site)
It has long been clear that writing for the reader, not for search engines, should be the first thing to do. However, it is interesting to know which styles will have the most chance of being understood by Google.
We list here several tips to promote the detection of entities by Google.
(As a reminder, the entities detected by Google NLP are visible via the Wikipedia links associated with the listed keywords)
How can you write to be understood by Google?
Emphasize the main entity of the page
Consider for example a page with the following sentence:
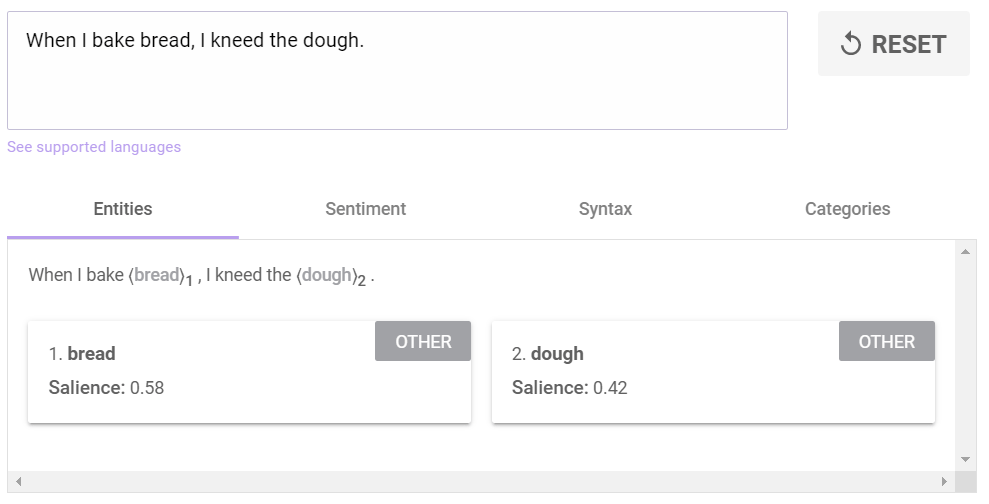
“When I bake bread, I kneed the dough“
Google will not detect any entity for this sentence (no Wikipedia link associated with the words)
If we now capitalize the two main entities:
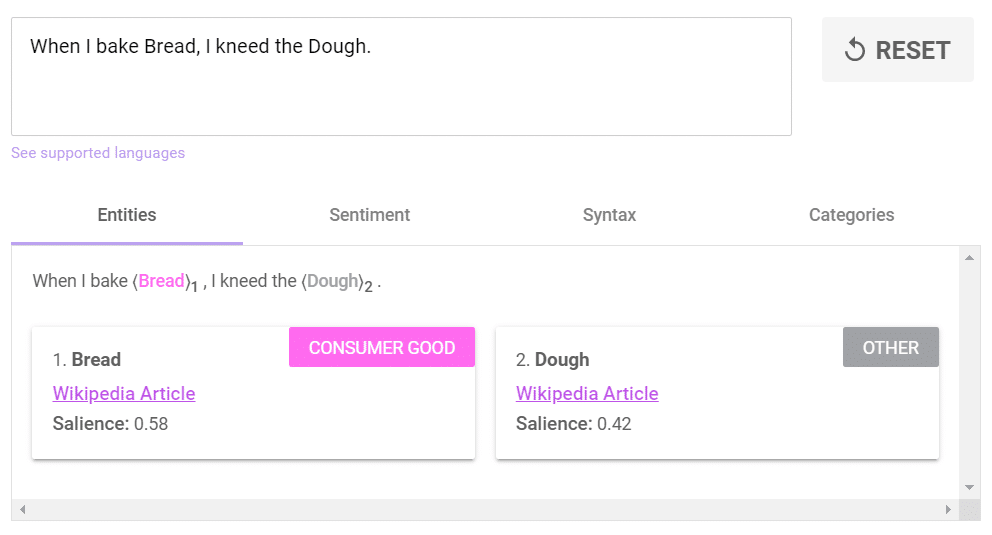
“When I bake Bread, I kneed the Dough“
In this case, Google will identify the entities Bread and Dough (presence of Wikipedia link associated with each word)
The problem is that using all caps may not be enough.
Google’s API is particularly reliant on the use of capitals. However, capitalizing important topics is not sufficient to ensure proper detection.
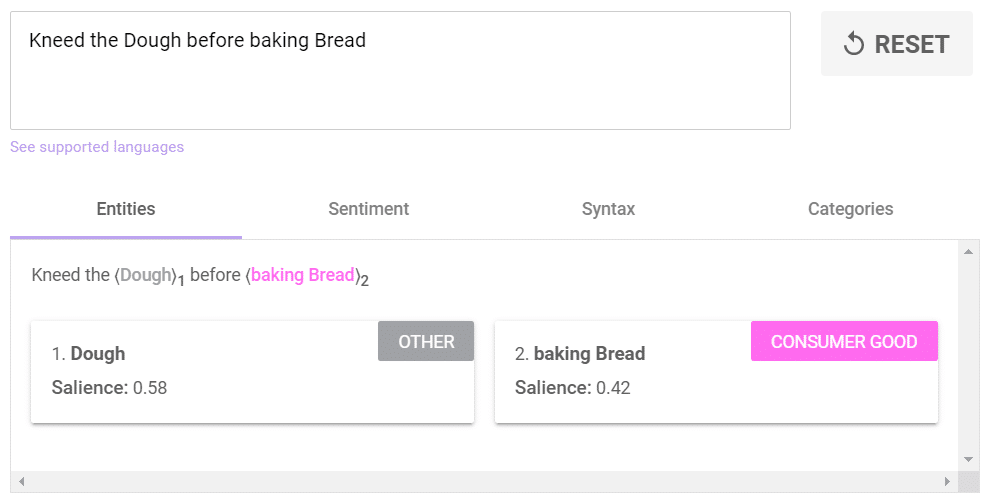
Thus, for the sentence “Kneed the Dough before baking Bread”, Google will not detect any entity.
Finally, what happens by capitalizing each word?
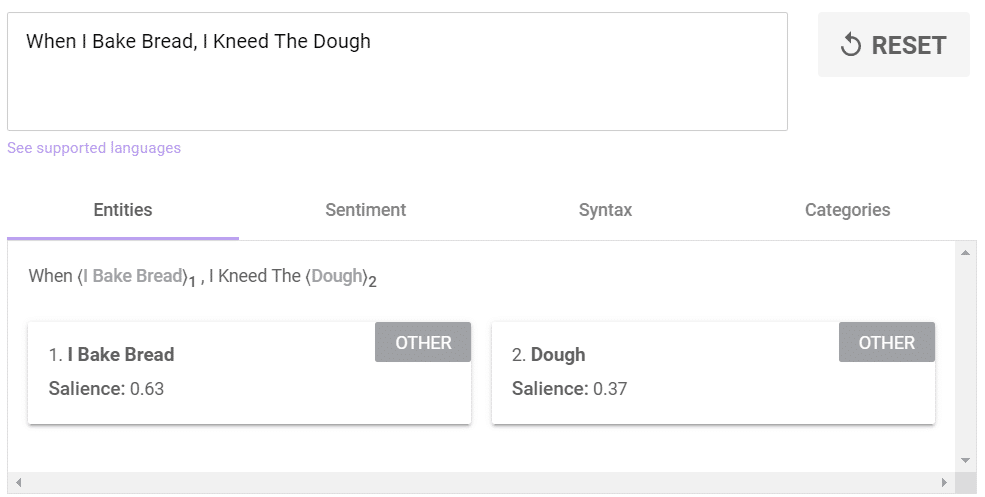
When I Bake Bread, I Kneed The Dough
The result is catastrophic: Google is no longer able to distinguish between important words in the text and secondary words, and no more entities are detected.
Tip N ° 1: Put your main entities in uppercase if possible (although that may not be enough). Do not use capital letters in your secondary words (especially for titles)
In order to maximize the detection potential of the main entities, it is also necessary to develop their context.
Develop the context around the main entities
Let’s take a French example in the field of jewellery with the following example, taken from a category page of a merchant site.

By submitting this text as it is to the Google API, it identifies 7 entities which we have translated into English for you. (Necklace, Pendant, Silver, Curb, Palladium, Titanium and Tungsten).
We can see here that the contribution of context ends up allowing Google to correctly detect the entity Money, which it was not able to detect above.
Now, if we submit the same text to Google, but one of the parts 1 to 4 above is removed, the API will only identify a single entity: Gourmette.
Several lessons can be drawn from this example:
Providing context is crucial for Google. In the example above, 4 types of context are provided:
- similar products,
- the material of the products,
- the recipients of the products (men, women, etc.),
- the brands of the products.
If just one of these contextual elements is missing, Google’s ability to detect text entities drops dramatically.
Finally, providing context allows Google to detect entities for plural words.
Tip N ° 2: add contextual entities, linked to your main entity.
Disambiguate the essential entities of the text
Now let’s take an example in English: this is a web page featuring SEO services for dentists in the US (yes, dentists out there have real websites!)
Here is the result of the entity analysis for this page. In blue, the first entities detected by InLinks, in brown, those detected by Google.
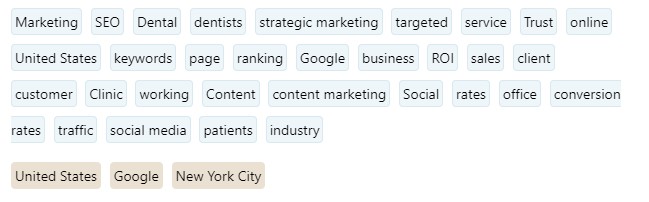
While the text is nearly 1,500 words long and covers most of the major SEO topics (keyword research, online marketing, local SEO, social media, etc.), the fact remains that Google has detected neither the Search Engine Optimization entity, nor the Dentistry entity (for dentist).
Why this disastrous result when the page editor took care to develop the context around all the activities related to SEO?
The reason is simple: the page addresses two separate topics, SEO and dentistry. For Google, these two themes have little to do with each other and the NLP algorithm ends up getting lost and no longer understanding anything.
Now, if we take the same text, and remove all occurrences of the word dental , what happens? Google now detects the SEO entity . It is therefore the influence of the word dental that prevents Google from fully understanding the meaning of the page.
Obviously, it is not possible in a page of this type to delete such an important word. So what to do?
The solution: explicitly disambiguate the important entities of the text.
For example by simply adding the sentence at the end of the text: SEO means Search Engine Optimization (in English of course), Google will correctly detect the corresponding entity.
Unfortunately, this trick does not work for all types of entities (especially dentists). It is then necessary to resort to a disambiguation via Schema.org, which we will see later.
Tip N ° 3: Text addressing several different themes within the same page will have more difficulty being “understood” by search engines than texts that focus on a single subject.
Use Schema.org to declare the main entities of a page
We have just seen that it can be really difficult to get the entities of a text to be correctly detected by Google by relying only on the editorial quality. In the event of a lack of context, of the multiplicity of topics covered on the page, or even of the presence or absence of certain words, Google’s detection capacity can vary considerably.
Fortunately, there is a miracle solution to explicitly declaring important entities of web content: it is Schema.org .
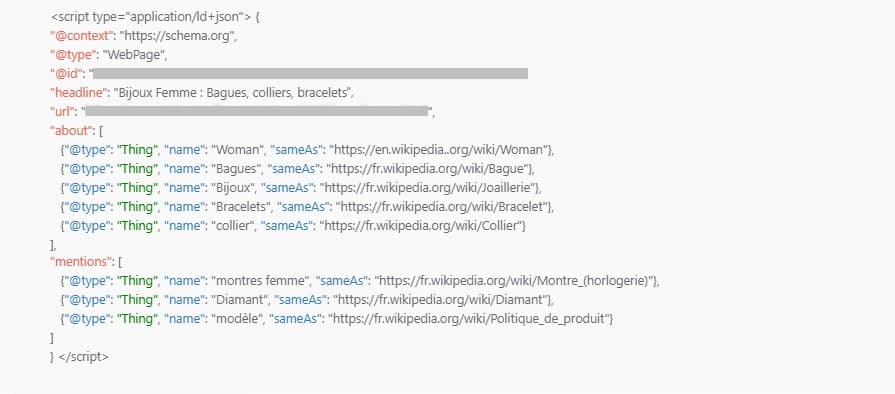
This type of Schema uses two particular tags:
- the About tag , which allows you to declare the main entities of the text (typically those found in the title of the page)
- the Mentions tag , which allows you to declare secondary entities, those which appear in the first paragraphs, or which are significant in relation to the rest of the site.
In each tag, it will thus be possible to specify, for each important word, the entity that corresponds to it, using the corresponding Wikipedia link.
In this way, the search engines (and particularly Google), will know exactly what are the important entities of the page and thus better index and categorize it.
Tip N ° 4: To secure the indexing of your entities by Google, use Schema.org with the About and Mentions tags on the most important pages of your site.
To learn more about setting up this markup (setting up which can be fully automated by InLinks), the following article will give you an overview of its SEO benefits: https://inlinks.com/help/case-study-does-webpage-schema-about-mentions-improve-rankings/
Conclusion
How to write your SEO content to optimize the detection of entities?
- If possible, capitalize your main entities (although this may not be sufficient). Do not use capital letters in your secondary words (especially for titles)
- Add contextual entities, linked to your main entity.
- Texts addressing several different themes within the same page will have more difficulty to be “understood” by search engines than texts focusing on a single subject.
- To secure Google’s indexing of your entities, use Schema.org with the About and Mentions tags on the most important pages of your site.
- Use Inlinks.net to automate and ease this process



superbe article de niveau groupe1; merci pour tous ces conseils.
Merci! C’est aussi en Francais: https://inlinks.com/fr/perspectives/comment-ameliorer-lindexation-de-ses-entites-par-google/
Rank math SEO plugin have this About and mention feature and till now i was confused how to use that. Thanks for this article.
Leave a Reply
Want to join the discussion?Feel free to contribute!