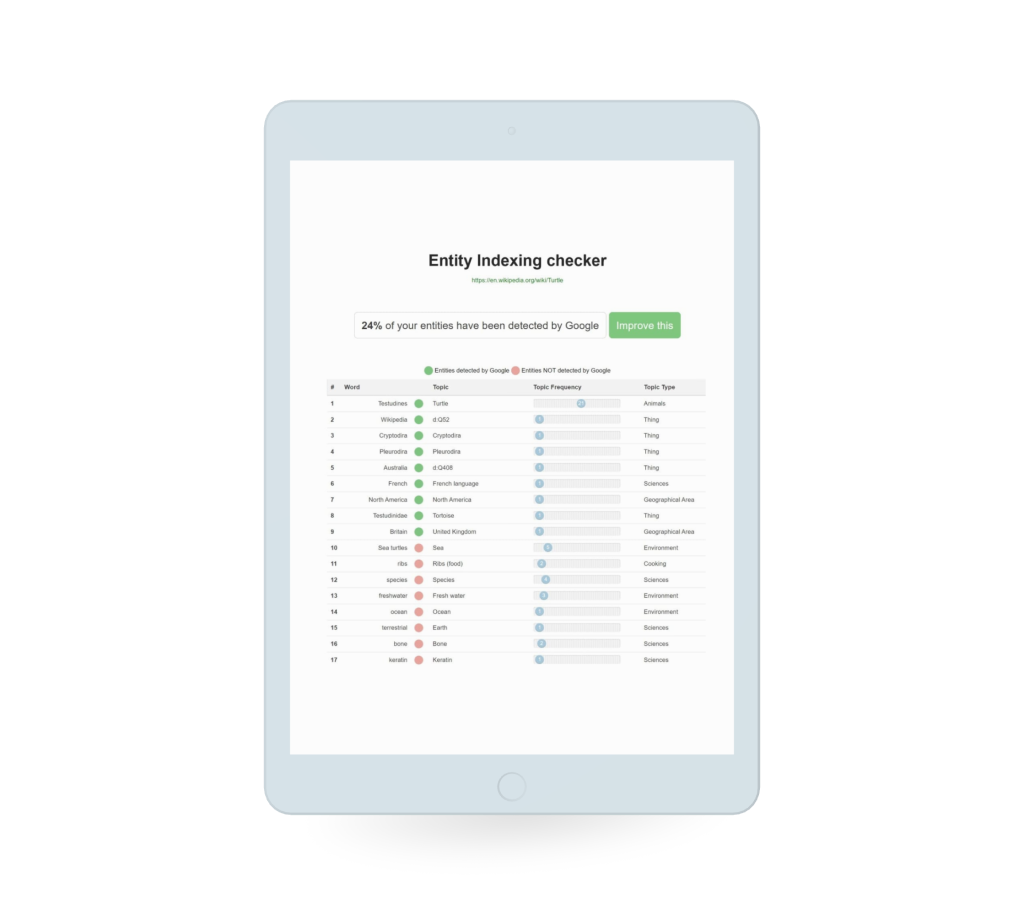
Just submit a URL to see which named entities have been detected by Google. Then click “Improve this” to get the schema.org markup that will optimize entity indexing of your content.
Google’s web crawlers analyze the text on web pages to identify and extract NEs. This process involves natural language processing (NLP) techniques that recognize patterns, grammar, and context to distinguish NEs from other text. By identifying NEs, Google can create a structured understanding of the content.
Once NEs are detected, Google classifies them into categories such as people, places, organizations, and more. This categorization helps Google organize and index the content more efficiently. For example, knowing that a particular word is a person’s name allows Google to associate it with relevant information about that person.
Google looks for semantic connections between NEs and other words in the text. For example, if a webpage mentions “SEO” and “search engine” in close proximity, Google’s algorithms can establish a relationship between the two NEs and assess that the word “SEO” refers to the Search Engine Optimization entity, as defined by Wikidata (https://www.wikidata.org/wiki/Q180711) and Google (https://www.google.com/search?kgmid=/m/019qb_)This helps in understanding the context and relevance of NEs within the content.
When a user enters a search query, Google’s indexing system matches the query terms with the indexed NEs. This enables Google to retrieve webpages that contain relevant NEs, making the search results more precise. For example, if a user searches for “iPhone,” Google’s indexing system will prioritize webpages that mention the NE “Apple Inc.” and its products, including the iPhone.
Google maintains a vast Knowledge Graph, which is a structured database of NEs and their relationships. This graph helps Google understand the world’s knowledge and connect NEs to related information. When indexing webpages, Google may update or enrich its Knowledge Graph with new information extracted from the web.
As a search engine and information retrieval system, Google relies on a combination of advanced algorithms and machine learning models to detect and index named entities (NEs) on web pages. While the search engine has made significant strides in improving its ability to recognize NEs, it still faces several challenges that make it difficult to detect all NEs accurately. Here are some key reasons why Google may not be able to detect all NEs in a webpage:
NEs can encompass various categories, including people, places, organizations, dates, products, etc. Google’s algorithms are optimized for detecting common NEs but may struggle with less common or specialized entities that do not fit into typical categories.
In some cases, the context in which an entity is mentioned can be ambiguous. For instance, a webpage might mention “Apple,” which could refer to the technology company or the fruit. Google’s algorithms need to analyze the surrounding text to determine the correct interpretation, and this can be challenging, especially for ambiguous or polysemous words.
Google operates in multiple languages and regions, each with its own nuances and linguistic variations. Detecting NEs accurately across different languages and dialects is a complex task, and Google may perform better in some languages than others.
The quality and structure of web content vary widely. Some web pages may have poorly formatted or unstructured text, making it harder for Google’s algorithms to identify NEs accurately. In contrast, well-structured content with clear markup can aid in NE recognition.
New NEs are constantly emerging, and existing entities may change or evolve over time. Google’s algorithms rely on existing data and may not immediately recognize newly coined NEs or updated information about existing ones.
Today’s web pages often contain text, images, videos, and other multimedia elements. Google primarily focuses on text-based content, so NEs mentioned in images or videos may not be detected unless explicitly tagged or described in the accompanying text.
In some cases, Google may deliberately avoid detecting or displaying NEs to respect privacy and consent concerns. For instance, it may not show NEs from password-protected or private web pages.
While Google employs sophisticated natural language processing (NLP) and machine learning models, these algorithms are imperfect. They may struggle with highly specialized or obscure NEs that do not have sufficient training data available.
Web content is dynamic and can change frequently. Google’s indexing process may not capture NEs that have been added or updated on a webpage after the last crawl.