

Google now starts to index your Javascript within seconds of its initial HTML crawl of your site. But that is not the full story when it comes to Javascript SEO. Even without being a programmer – this stuff matters for SEOs (and inLinks users). This post goes behind the scenes a little to get the inside scoop.
Javascript was traditionally hard for crawlers because many of the web resources that are called by the page are not visible in the raw HTML. So if you use the “view source” option to look at code, stop immediately and use the “inspect” option in Chrome or the “inspect element” option in Firefox instead. This will then show more of the code that the browser (and therefore the user) sees and interacts with.
Earlier this month I was lucky enough to be invited to Google’s Webmaster conference day in Zurich. I wrote up notes on two other presentations at the time on my blog but wanted to save Martin Splitt’s presentation on Javascript: “Javascript Indexing Behind the scenes” (I may have misquoted the title) because I needed to digest it a little more and add some personal points of view.
Martin Splitt’s take on Javascript Behind the scenes
A note to the reader here – I wanted to do more than just repeat Martin’s presentation parrot-fashion, so I have extrapolated by using my own quotes which I am sure Martin would NOT always be happy to condone or say. The SEO Learning bits are ME, not Martin. Martin is welcome to correct me, but may prefer not to comment on my take.
Why the obsession with Javascript?
Martin points out that what the user sees is not about the code, but about what the Browser interprets the code. Google wants to see what the user sees. So this means parsing .js first (where possible) and then looking at the DOM after the .js is parsed.
SEO Learning: Stop using the “viewsource”options in your browser to look at the underlying code… you will probably not get an accurate view of what users (or search engines) see. Better is to use the developer tools in Chrome or Firefox.
Dixon
Undestanding server-side and client-side rendering
Any SEO expert dealing with Javascript needs to understand 2 very important concepts, and these are server-side and client-side rendering. In a nutshell, server-side rendering involves a browser or a Googlebot receiving an HTML file that describes the page in its entirety, this makes it easy for search engines to understand server-side rendered Javascript content.
On the other hand, client-side rendering involves a browser or a Googlebot getting a blank HTML page during the initial load time, then the Javascript downloads the content from the server and updates the screen.
How does Google pull in the Javascript?
The challenge with processing Javascript is that it takes a huge amount of time (relatively speaking) to render. Martin used an example which I did not make a note of…. but I took a photo and he points out that the blue bit is the layout time in the image:

Anyone can use their Pagespeed insights tool. Take their own Japan homepage, which loads in a very impressive 1 second:
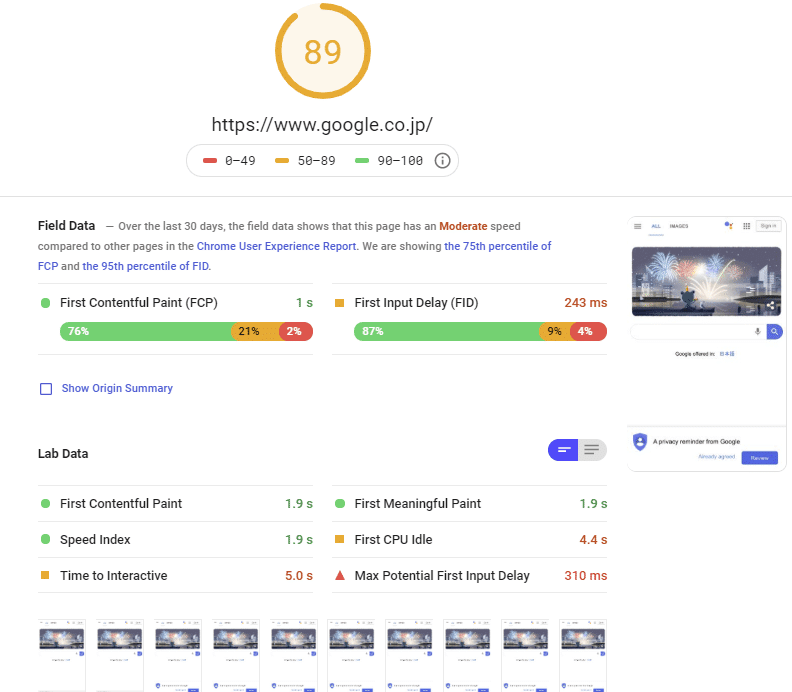
Pulling in raw HTML is a very different challenge from pulling in “rendered” HTML, as the rendering is done after the HTML is called by a browser. So this increases the load time. At scale, this has big issues for web crawlers.
SEO Learning: If a search engine wanted to crawl and render a trillion URLs a day at that 1 page per second, let’s do some possibly dubious maths: 1 trillion seconds = 2,777,778 hours. There are only 24 hours in a day, so you would need 115,741 headless chrome instances open 24/7 to render all this. When you note that this was a fast example, you can imagine that you would need more than this… so a search engine cannot scale .js rendering in this way. Martin put up a diagram or two, which I am recreating partly from memory.
Dixon
Back to my take on the presentation. Google has a thing called their “Web Rendering Service” (WRS). After the initial crawl, the page goes into the rendering queue, then the rendered DOM goes back into the processing path.
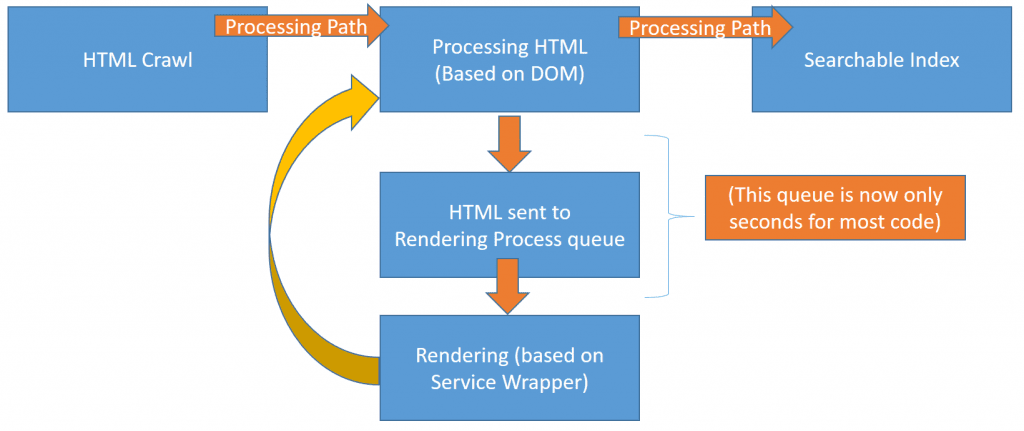
He couldn’t go too much into that but suggested Puppeteer as an equivalent technology that he could talk about. They work like this:
Task 1: Decide on Viewport settings
When rendering your page, they first need to decide what screen size should their system simulate. Essentially, this is the difference between indexing as if you were looking at the site on a mobile versus looking at the site on a desktop.
SEO Learning: Mobile First indexing has a HUGE amount to do with Javascript rendering. Googlebot crawls the raw HTML, but when it is rendered, it gets changed and reintroduced almost as if it was a new Googlebot crawl. Also – this is why there is not a mobile index and a desktop index. it is ONE index, but the way the pages are rendered may differ, depending on the choice of viewport here.
Dixon
Task 2: Decide on Timeout or abort options
If Page A takes 2 seconds longer to render than Page B, does their Web Rendering Service make every page wait 2 seconds longer? this is not an easy question to answer and is part of Google’s secret sauce. One thing they do – and this is very important for SEOs – is cache as much as they can (in parallel to the WRS). They use what they call a “Service Wrapper” for this. When you use testing tools you might access the WRS, but you will not see what is cached. When you are testing, you obviously want to test the live version, not an old cache, but Google needs to be more efficient at scale. They don’t want to do “live”… they want to do “fast”.
SEO Learning: Just because Google has recrawled and indexed your page after a rewrite, it might not have rendered all of the .js files correctly. That may happen later after they have updated their “wrapper”.
Dixon
There is also a “Pool manager” with a bunch of headless browsers running 24/7. They do not install service workers on demand. John Mueller had already said at this conference that the .js queue time was a median length of 5 seconds but might be minutes for the 90th percentile and above of all sites. This is a massive improvement on the Matt Cutts’ era, but it is not the whole story…
SEO Learning: Google’s .js rendering queue time is NOT the same as the Render time! Infact, the render time is a bit of a misnomer, because of the “service wrapper” which may have done some of the work weeks ago (maybe on an old version of a .js file) and is yet to render the latest version of another .js file.
Dixon
Some Tips and Tricks for Javascript SEO
Having seen how Google renders Javascript – as far as Martin was at liberty to explain it – he offered some very useful SEO tips off the back of this insight.
Tip 1: Simple Clean Caching
Martin suggested using content hashing on your files so that Google could easily see when a .js file has been updated or changed. For example, you can use an open-source library like Webpack to do this.
Tip 2: Reduce Resource Requests
For example, make the api requests serverside, then make just one request browser-side. Also, you can create one minified request to import all your apps. However – this tip came with a rather important caveat: Avoid one large bundle that needs to be sent on every page load. One single change means that the content hash changes page by page, so you lose the caching benefit. Translated – make sure not to bundle apps that change between pages.
Tip 3: Avoid Javascript for Lazyloading
There are several useful posts on how to do Lazyloading without Javascript. Although Martin didn’t suggest any one method, he did suggest avoiding Javascript if you want to lazyload stuff. Frankly, I am too lazy even to lazyload, so I’ll just leave that tip here.
Tip 4: Use the Tools
The Javascript team are pleased with their rendering tools, such as their “Fetch and Render” tool and recommend that you use them with gay abandon (my words, not Martin’s).
There was also a tip about using “lodash” and when using gzip, only sending the functions you need for the page to load in the gzip file, otherwise Google has to unpack the whole file to reread code it already had happily cached. Lodash is all a little above my paygrade, so again I leave this as a note for cleverer people to take on board.
Bonus Tip: SEO and Ajax
Although this was not a topic that Martin dwelt on in Zurich, John Mueller (who was also at the conference) has covered the most important issue in a video.

Ajax has been a problem for SEOs for many years. In particular, Ajax has a tendency to use hashtags (#) in URL structures. Anything after a # symbol in a URL is not strictly part of the main URLs so in the past, search engines stopped and only indexed the URL before the # symbol.
Luckily, now that Google renders the page before indexuing the content, this is no longer an issue for SEOs as the video explains.
Some Final Thoughts
This post is important to be on the inLinks blog because I occasionally get questions about whether search engines can read the injected code and schema that inLinks generates for your site. The answer is… for modern engines… absolutely! Moreover, they can read the code quickly and when they do, they ONLY see the DOM with the injected code when they analyze your content. There may be a delay, but this should not be consequential for SEOs. Google’s ability to crawl Javascript seems to be a dominant one and is a real USP between them and other search engines. They are rightly proud of this.
I would also recommend (if you have not done so already) watching some or all of Martin’s Javascript for SEOs videos if you actually have to CODE rather than pontificate. In that case’ you might like to get your intelligence from Google itself, rather than having me inject my thoughts and potentially twisting the story (which SEOs are indeed prone to do, but I hope I have not). Martin is also pretty accessible on Twitter @g33konaut. So am I @Dixon_Jones.



Leave a Reply
Want to join the discussion?Feel free to contribute!