

Since Google’s announcement of schema.org on June 2, 2011, the number of terms the vocabulary describes, Google’s consumption of its classes and properties, and the number of websites publishing structured data markup have grown to a level nobody dared to predict more than a decade ago.
According to information released by Web Data Commons, 1.7 billion HTML pages – out of 3.4 billion HTML pages crawled – contain RDFa, Microdata, or JSON-LD statements embedded on those pages. Suggesting that, according to the data, a whopping 50% of the pages that make up the open web now contain some semantic metadata.
A result that predominantly has been achieved through the efforts of 1 company: Google – due to a combination of its market dominance and the promise of potentially rewarding the inclusion of structured data markup with attention-grabbing Rich Snippets.
A hooray for all of us – the people who, step by step, help turn the promise of a semantic web into reality by producing semantic metadata at a web scale!
Although people (especially SEO specialists) can also be the cause of…
some pretty obnoxious forms of markup abuse, overuse, and screw-ups.
Sometimes intentionally and (semi-)maliciously, and other times because we are competing for the same SERP real estate space through equal means – leading to the point that the value of certain markup-driven search features, like FAQs, evaporated because mediocre content was suffocating the SERPs.
And then there are those who attempt to produce something meaningful and out-of-the-box yet who, with the best intentions, have unintentionally shot themselves in the foot because they went overboard – causing their markup to be ignored by Google and rendering the effort mute.
Some people believe that the more markup a page contains, the more Google can make sense of things. Which supposedly helps pages rank better – for things they probably should not rank for – by adding tons of markup that is nowhere to be found in any documentation by any data consumer (like Google, Bing, or Facebook).
Acts based on assumptions about the effects of structured data markup
SURPRISE! 🥳 Schema markup is not a form of fairy dust to sprinkle on your content to make it fly.
Just because you annotated things does not imply Google (or any other data consumer) will use those annotations. Features based on markup do not ‘automagically’ appear after you define abracadabra. Search engineers need to create features first before search engines can make use of any markup out there.
Schema.org terms that are unmentioned in Google’s documentation will probably not be used by them until these have been documented or mentioned by its representatives.
Something that does not imply you should never go beyond the beaten path, as sometimes it seems obvious where things are heading. Sometimes, new opportunities justify being an early adopter.
However, as an early adopter, you should be aware that finding an ROI can take a while. And you should also be willing and able to take a loss.
Sometimes, things turn out differently than we (and search engineers) imagined they would. And if you can not afford to make such risky investments, then DON’T. Just stick to the documentation. Most of the time, the basics are all we need – especially regarding search result features.
Named entity stuffing ≠ semantic SEO
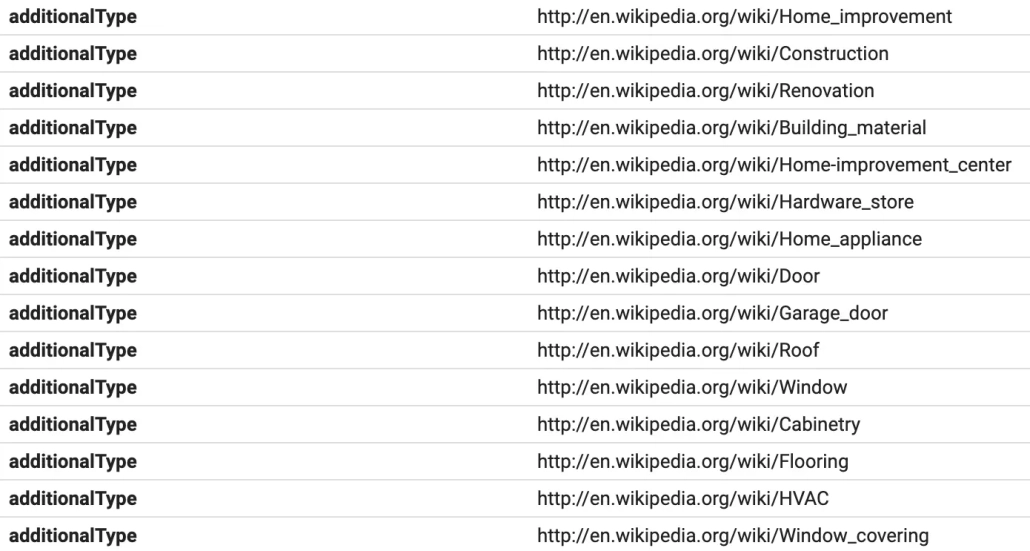
Above is a screenshot of an illustrative example of some of the over-the-top statements you can find out there. In this case, statements about a HomeAndConstructionBusiness, whose markup likely is a misguided attempt at associating that business with some of their most important keywords.
The bad news for them is that instead of successfully associating their business with the products they sell and any services they provide, they introduced ambiguity by stating their business = Home improvement = Construction = Renovation = Home appliance = Door = Roof = Window = Flooring = etc.
The equivalent of which would be me saying I am a Person = Ears = Eyes = Nose = Glasses = Mouth = Beard = Legs = Jeans = Feet = Socks = a nearly endless list of possible statements, of which I should not have to explain to you why these make no sense, nor that they will ever serve any purpose.
This represents an attempt at semantic SEO using a buckshot approach instead of the delicate and thoughtful approach it needs, like how a plastic surgeon treats patients with scalpels and the utmost precision.
You will not get any results by acting like an inexperienced hunter, shooting around (while dreaming of a Gatling gun), hoping to hit something, no matter what, as long as it is a hit.
Web pages about everything = lack of focus and little value
Some people believe that describing every single (implied) entity or concept on a page is a great way to convince Google these are the terms a page is relevant and should rank for – as if it is that easy to influence (or, should I say, manipulate) search engines.
<sarcasm>Why not throw PBNs for links into the mix? And while you are at it, how about publishing some AI mass-produced content about those topics to build up your lexical authority, eh?</sarcasm>.
When content does not explicitly mention the things and concepts the markup describes, why would you assume that doing so through Thing.sameAs or DefinedTerm statements would represent anything of value for machines?
Do you maybe believe (the people behind) abstract machines are so gullible not to check what your markup serves to machines and compare it to what you serve to people?
Main entities = justification for why content should exist and rank
Describing the aboutness of pages should be an act of describing those things that justify why a piece of content should exist. That one thing (or a handful of) that content tries to capture and deliver to people.
That which probably coincides with your interests as an organization or author. After all, why else would you publish content about certain things if it does not serve your interests?
Structured data markup should be nothing other than a machine-readable translation of a page’s most important entities, possibly extended with related things. But if the content is so elaborate that it requires tons of named entities to describe it, there better be a good reason for that.
Most content that requires a large number of annotated entities tends to be poorly designed, structured, or written ambiguously. Content that tries to serve too many goals or serves no clear goals at all.
The type of content that does not tend to satisfy people’s needs and, therefore, does not qualify to rank well, get Rich Results, or get Featured Snippets. The type of content that should be taken back to the drawing board instead of stuffing it with markup as if it is a Thanksgiving turkey.
How to create and maintain structured data markup that drives results
1. Start by creating an abstract describing the task at hand
Before creating any schema markup based on any content, it is always a good idea to start by creating an abstract about a project. An abstract that defines the context of what you are about to do and also defines some boundaries. Something that answers questions like (but not limited to):
What is the intended purpose of structuring any given data?
- Is it to define an Information Presentation Layer, like a web page or a dashboard,
- Is it to enhance Google’s search results through Rich Results and increase content’s visibility,
- Is it to facilitate Data Interoperability (data exchange between systems), like feeding job board, hotel booking, or marketplace sites through (XML) feeds, Google Shopping through markup embedded on your pages, or feeding annotations back into your analytical systems to unlock enhanced forms of Data Science and Machine Learning.
What do you want people to achieve on a page (its goal)?
- Learn: Educate people about a topic (e.g., how to accomplish a task they are struggling with),
- Engage: Encourage interaction (e.g., sign-ups, downloads, participate in a webinar),
- Transact: Drive conversions (e.g., sales, leads, additional page (=ad) views).
What is the main entity of a page?
- On a recipe page, this will likely be a
Recipe(e.g., “Classic Lasagna”), - On an e-commerce page, this will likely be a
ProductGroup(e.g., “Cotton Summer T-shirt”) and itsProductvariants (e.g., “XL Yellow Cotton Summer T-shirt”), - On news sites, this will likely be a
NewsArticleabout, and whichmentions, certain topics. (e.g., “Breaking! There is no news today – Read the story to find out what did not happen.”).
Which boundaries do you set for the depth of information on a page?
- Scope: What falls within the set goals? (e.g., summaries about an article’s topics, a list of awards on an artist’s bio page, corporate and legal identifiers on an organization’s About page),
- Exclusions: Things that do not contribute (directly) to the primary goals. (e.g., a 1.500-word article + inspiring photos and videos describing the experience you will get out of a dish before finally telling the reader which ingredients they need and how to prepare a dish – on a recipe page).
Which data needs to be annotated and turned into information?
- Entities: Organizations, people, products,
- Creative works: Paintings, books, movies,
- Events: Past, present, or future events (e.g., a concert or a graduation),
- Attributes: Properties associated with entities and the values that define them,
- Relations: Connections between different entities,
- References: Links to resources about entities and concepts,
- Concepts: Thoughts and ideas that emerge through relations (e.g., “Italian cuisine” is related to lasagna, or “Glamping” is related to travel accommodations).
2. Copy and paste a basic schema markup template
You should start with Google’s Structured Data Feature Guide and read the latest specs of the class (type) you want to write a markup template for ↦ A method for preventing yourself from making mistakes by writing markup based on memory or work you have done for previous projects.
And because Google constantly works on improving its guidelines and examples, copying its code examples as a basis for your markup means you will be well on your way to creating what you need ↦ A method far more efficient than writing every line by hand and which helps you to prevent wasting your time working on things they do not (or are not likely to) support.
3. Expand on the basics until you have reached your goals
While customizing your structured data markup template(s), translate what is on the page AND annotate those things your abstract highlights. This way, structured data markup can act as a guide on how to improve the content itself ↦ A very efficient and effective method of clarifying to others how to enrich content.
Though take note. Everything mentioned in any markup should always be present on the page. Do not add things to the markup – without – including it in the content.
Not just because Google will otherwise ignore it, but because there is a 99% chance that what you find interesting for machines is also very interesting for people (our target audience, remember them?).
Focus on Quality & Accuracy over Quantity
Semantic SEO is not about annotating every entity or concept on a page. It is about conveying relevant, high-quality information that serves specific goals. You should avoid over-annotation and limit yourself to making precise and informative statements about the main entities involved.
Annotate what matters most, and try not to be overly specific. It is often best to choose the more generic schema.org class for describing something rather than going out of your way to explain something for which there (currently) is no vocabulary.
It is often the case that less = more. The less effort it takes to process structured data, the more chance information has to be used in different channels, media, and formats.
4. Be agile and continuously release, monitor, and iterate improvements
Many make the mistake of releasing markup, monitoring it in Google’s Search Console for a month or two, tinkering until it is all done, and then wrapping up and no longer monitoring nor maintaining any of it.
Only to look at it again, an N amount of time down the road – after Search Console suddenly started screaming tons of warnings and errors. Ones that often could have been avoided (at a much lower cost than compared to ad-hoc fixes).
Consequences of the reality that most websites are dynamic objects. Page layouts and the information these contain change, datasets evolve, and new content types get introduced.
Markup maintenance & development should be part of the overall process of updating a site. If not, markup tends to break, parts of the info will mysteriously disappear or contain the wrong data, or new page types end up including markup templates containing false information.
Situations that sometimes lead to a site losing (some of) its Rich Results without anybody noticing it or knowing why that happened. Until somebody finally notices a dip in revenue and panic sets in, because there is no room on the development backlog.
Or, neglecting to prepare for new features about to roll out in search and missing out on opportunities for many months in a row due to – yet again – the forever overflowing development backlog.
Issues and opportunities that would have been easy to fix or prepared for if somebody had continuously curated the markup – while improving the site – by constantly releasing small, simple, and cheap fixes and improvements without being too much to fit on the development backlog.
In summary
Creating interoperable structured data (markup) involves understanding its context, defining its purpose, goals, and main entities, setting boundaries, and focussing on the quality and accuracy of its statements.
You should continuously monitor and update your structured data to prevent issues, keep things in sync, and always already be ready for new opportunities.
Once you can effectively and consistently (re)produce results, you are ready to attempt to go above and beyond by publishing an elaborate (schema markup) story like I did. One intended to be a Knowledge Graph in itself, thus justifying the presence of hundreds of entities and concepts. One that contains so much substance schema.org’s validator causes a browser to go: “Aw, Snap!”.



Leave a Reply
Want to join the discussion?Feel free to contribute!