

Ce n’est un secret pour personne, la manière dont nous abordons l’optimisation des moteurs de recherche est en train de changer. Il ne s’agit plus seulement d’insérer les bons mots-clés ou d’essayer de déjouer les algorithmes. Aujourd’hui, les moteurs de recherche comme Google s’attachent à comprendre le contexte, le sens et les relations. C’est là qu’intervient le référencement d’entités, une approche plus intelligente et plus stratégique qui permet à votre contenu de se démarquer.
Dans ce guide, nous allons vous expliquer comment vous pouvez utiliser les entités pour obtenir un meilleur classement dans les moteurs de recherche, vous rapprocher de votre public et, en fin de compte, développer votre activité.
Voici les sujets que nous allons aborder :
- Qu’appelle-t-on une entité et pourquoi le concept est-il si important ? Nous allons faire une petite analyse de la façon dont les moteurs de recherche se sont peu à peu émancipés des mots-clés dans l’objectif de mieux comprendre les sujets et les concepts.
- Comment, grâce aux entités, utiliser les outils Google à votre avantage ? Du Knowledge Graphe aux services NLP, nous allons vous montrer comment exploiter les mêmes ressources que Google utilise pour identifier et classer les contenus.
- Comment transformer les entités en profit : vous allez découvrir en quoi le fait de cibler des entités permet d’attirer le bon public, de générer des conversions et d’augmenter votre chiffre d’affaires.
Que vous soyez un spécialiste du marketing, un chef d’entreprise ou simplement curieux de connaître l’avenir du référencement, ce guide regorge de conseils pratiques qui vous aideront à garder une longueur d’avance. Préparez-vous à améliorer la visibilité de votre contenu, son classement, et donc, sa rentabilité.
Sommaire :
1. Qu’est-ce que le référencement d’entités ?
- Le langage
- L’aspect technique
2. Google Search et les entités
- Comment Google détecte-t-il les entités à l’aide d’un NLP ?
- Comment Google utilise-t-il les entités une fois qu’elles sont repérées ?
- Pouvez-vous aider Google à détecter des entités sur vos pages ?
3. Quels sont les services Google qui utilisent les entités ?
- Google Business
- Google Maps
- Google Discover
4. Comment l’optimisation des entités peut-elle augmenter votre chiffre d’affaires en ligne ?
- La stratégie
- Les résultats
- Comment devenir une entité dans le Knowledge Graph de Google ?
- Comment une entreprise peut-elle devenir une entité dans le Knowledge Graph de Google ?
5. Entités, LLM et IA
6. Conclusion
9
1. Qu’est-ce que le référencement basé sur les entités ?
La question du langage
En termes simples, une entité est une « chose ». Il ne s’agit pas du mot qui décrit la chose, mais du concept abstrait associé à cette chose. Prenons un exemple :
Lorsque vous lisez le mot « chien », êtes-vous en train de.. :
a) réduire des lettres à leur valeur nominale sans donner aucune signification au mot, car il n’est qu’un gribouillis sur une page ?
b) visualiser, dans une certaine mesure, ce que vous savez être un chien ?
Je pense que la deuxième hypothèse est probablement la bonne. En effet, notre cerveau est toujours à la recherche d’informations à associer à des stimuli visuels/physiques/émotionnels (comme le mot « chien »), de sorte que nous ne soyons pas constamment dans l’inconnu. C’est une manière de rendre le monde plus prévisible et plus compréhensible. En lisant, vous puisez inconsciemment dans votre base de données interne de connaissances pour chaque nouvelle « chose » que j’écris, donnant un sens à mes mots parce que vous savez ce qu’ils signifient au lieu de vous contenter d’admirer leur orthographe, aussi jolie soit-elle.
La même théorie s’applique aux ordinateurs.
Alors qu’un être humain a une réponse biologique automatique à l’acquisition de connaissances, les ordinateurs ont besoin d’énormes bases de données et de beaucoup de codage pour parvenir à quelque chose de similaire. Au lieu de traiter des mots ou des phrases isolés (approche par mots-clés), les moteurs de recherche cherchent désormais à savoir ce que les mots signifient réellement et dans quel contexte ils sont utilisés.
A cela, il y a plusieurs raisons :
1. Déterminer l’utilité des page
Contrairement à ce qui se passait auparavant, aujourd’hui si quelqu’un veut écrire une page sur les chiens et qu’il n’écrit le mot « chien » que 100 fois, il se pourrait que malgré tout, l’article soit perçu comme étant utile. En effet, désormais les entités et les bases de données d’entités aident les moteurs de recherche à déterminer la qualité et la pertinence des pages en examinant le contexte entourant le concept de « chien » plutôt que la densité ou la position des mots clés. Si vous abordez toutes les thématiques que la base de données sait être vraies à propos des chiens, vous avez beaucoup plus de chances d’être considéré comme faisant preuve d’autorité, car vous parlez de manière cohérente, significative et utile de la « chose », même si vous la mentionner peu.
2. Comprendre et développer les requêtes de recherche.
Comment expliquez-vous qu’après avoir tapé une requête sur Google, d’autres questions en lien avec le sujet apparaissent comme par magie dans la rubrique « Autres questions » ? C’est parce que les mots que vous avez tapés font partie d’un réseau de concepts que les moteurs de recherche connaissent, et qu’ils savent connectés entre eux. Il s’agit d’entités qu’ils sont capables de relier les unes aux autres en utilisant le contexte fournit par leur base de données d’entités, les fameux « graphes de connaissances ».
3. Réduire la puissance de traitement.
Imaginez que vous deviez vérifier chaque mot individuellement sur l’ensemble du net pour en trouver la signification au lieu d’avoir juste, comme nous le faisons machinalement, à lire des phrases pour être à même de les comprendre aussitôt. C’est la même chose pour les moteurs de recherche.
Dixon Jones fait un tour d’horizon de la question sur cette vidéo :
V

La question de la technologie
Une entité est « une personne, un lieu ou une chose unique au sujet de laquelle des données peuvent être accumulées ». Dans un contexte de référencement, ces entités sont stockées dans ce que l’on appelle une base de données relationnelle, ce qui signifie que les entités incarnent un identifiant unique qui est ensuite complété par des informations spécifiques qui sont en relation.
L’identifiant unique ressemble à quelque chose comme ceci :
« MREID=/m/23456 » ou “KGMID=/g/121y50m4”.
MREID signifie Machine-Readable Entity IDs (qui est un terme plus général) et KGMID signifie Knowledge Graph Machine ID (qui est propre à l’insaisissable et impénétrable « Knowledge Graph » de Google).
Une entité existe si elle possède un identifiant unique. Elle est relationnelle car les informations contenues dans cet identifiant unique (ID) peuvent être comparées et connectées à d’autres. Cela montre le chevauchement ou les « similitudes sémantiques » qui existent entre des concepts uniques, le tout se passant à très grande échelle.
Une entité existe si elle possède un identifiant unique. Elle est relationnelle car les informations contenues dans cet identifiant unique (ID) peuvent être comparées et connectées à d’autres. Cela montre le chevauchement ou les « similitudes sémantiques » qui existent entre des concepts uniques, le tout à très grande échelle.
L’une des premières bases de données relationnelles notables était l’encyclopédie semi-structurée Freebase, un peu comme l’est aujourd’hui Wikipédia. Chaque article portait un titre spécifique, recevait un identifiant unique, puis était enrichi d’informations par des humains. Les informations contenues dans les articles pouvaient se chevaucher et se lier les unes aux autres, créant ainsi un réseau de connexions entre les entités en fonction de leur similarité sémantique.
L’image ci-dessous est un graphique de liens de Wikipédia. Il montre à quel point cette base de données est complexe et incroyable.

Figure 1 – Matt Biddulph – Royaume-Uni, CC BY-SA 2.0 <https://creativecommons.org/licenses/by-sa/2.0>, via Wikimedia Commons
Elle démontre que les bases de données relationnelles permettent aux ordinateurs de « penser » de la même manière que nous (dans une certaine mesure, bien sûr…) en puisant dans une base de données remplie d’éléments qu’ils connaissent déjà et en établissant des liens avec ces éléments dans un contexte plus large. Ils savent ainsi que les chiens ont une forte corrélation avec les chats et un lien faible (mais pas complètement insignifiant) avec la Joconde. La preuve :

Figure 2 – https://www.deviantart.com/webartgallery/art/Mona-Lisa-Mirage-The-Canine-Illusion-1005730447 via Wikimedia
2. Recherche Google et entités
Comment Google réussit à détecter les entités à l’aide du NLP
C’est bien de savoir qu’une telle base de données existe et que Google l’utilise pour comprendre plus rapidement et plus finement votre contenu, mais c’est encore mieux de saisir comment cette base de données est utilisée pour analyser des milliards de pages et à des trillions de mots.
Le principal outil qui permet que cette base de données soit opérante est ce que l’on appelle un algorithme de traitement du langage naturel (NLP). Il s’agit d’une branche de l’intelligence artificielle permettant d’interpréter des passages de textes écrits par des humains de manière significative, au lieu de se contenter d’une multitude de lignes gribouillées et de codes sur une page.
Voici comment cela fonctionne :
Étape 1 : L’étape de « prétraitement »
Elle prépare le texte brut à l’analyse des données.
- Tokénisation : Division du texte en tokens (mots, phrases ou sous-mots, ponctuation).
- Suppression des stop-words (mots creux) : Suppression des mots courants mais non informatifs (par exemple, « et », « le »).
- Simplification sémantique : Réduction des mots à leur forme racine à l’aide de règles (par exemple, « running » → « run »).
NB : cette technique s’avère parfois mal adaptée à l’analyse du langage.
- Lemmatisation : Conversion des mots à leur forme de base en fonction du contexte (par exemple, « better » → « good »).
NB : cette technique s’avère parfois mal adaptée à l’analyse du langage.
- Étiquetage POS (Part-of-speaking tagging) : Attribution des éléments du discours (par exemple, nom, verbe) aux mots.
NB : L’efficacité de ce balisage dépend du langage utilisé. Certains, comme le mandarin. s’y prêtent mal.
- Normalisation du texte : Standardisation du texte en minuscules, suppression de la ponctuation et correction des fautes d’orthographe.
N
Étape 2 : L’extraction des caractéristiques
Elle transforme le texte en chiffres.
- Sac de mots (BoW – Bag of words) : Représentation du texte sous la forme d’une matrice éparse du nombre et de fréquences de mots.
- TF-IDF (Term Frequency – Inverse Document frequency : Représentation pondérée qui compare la fréquence des termes (TF) présents dans un article avec la fréquence inverse des documents (IDF) c’est-à-dire celle qui recense la présence de ces termes dans l’ensemble des textes recensés traitant du même sujet, ceci afin de réduire la pondération des mots communs.
- Emboîtement nominal : Représentations vectorielles denses des mots qui capturent les relations sémantiques (par exemple, Word2Vec, GloVe, FastText).
- Plongement lexical (Word embedding) : Représentations de mots sensibles au contexte, dérivées des méthodes d’apprentissage des transformeurs génératifs tels que BERT ou GPT.
Étape 3 : La construction d’un modèle
Différents algorithmes peuvent être utilisés pour analyser les données numériques collectées à l’étape 2.
- Modèles basés sur des règles : Ils utilisent des règles ou des modèles (par exemple, des règles de grammaire) pour analyser le texte.
- Modèles statistiques : Ils utilisent des probabilités pour prédire des archétypes de langage (par exemple, les modèles de Markov caché).
- Modèles d’apprentissage automatique : utilisent des algorithmes tels que Naïve Bayes ou SVM pour classer ou regrouper des textes.
- Modèles d’apprentissage profond : utilisent des réseaux neuronaux pour comprendre le langage
- RNN (Recurrent Neural Network) et LSTM (Long Short Term Memory) : traitent les séquences, comme les phrases.
- CNN (Convolutionnal Neural Network) : extraient les caractéristiques importantes du texte.
- Transformateurs : Modèles puissants tels que BERT et GPT qui comprennent le contexte des phrases.
Étape 4 : L’inférence
C’est là que se dévoile, enfin, la véritable signification du texte.
À ce stade, les données sont prêtes à être analysées et répertoriées. L’un des principaux processus d’inférence utilise la reconnaissance des entités nommées. C’est là qu’intervient le graphe de connaissances. Une page est transformée en données numériques à partir des trois premières étapes, puis la base de données est utilisée pour extraire les entités reconnues dans le texte. Voici une représentation visuelle de ce processus :
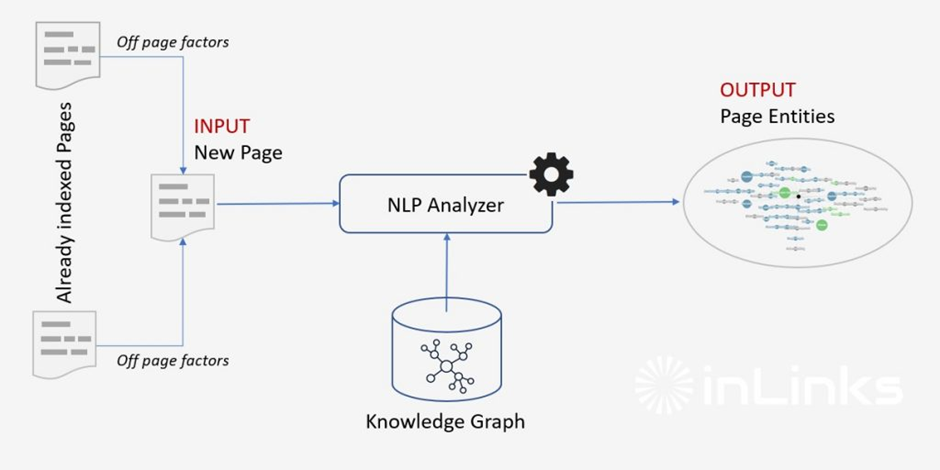
La partie concernant les « pages déjà indexées » sera abordée un peu plus loin dans l’article.
Ce qu’il faut savoir à ce stade, c’est que, à moins que vous ne soumettiez des pages orphelines, votre contenu n’existe jamais de manière isolée, et il sera traité dans sa globalité par le NLP, comme un réseau. Toutes vos pages comptent lorsqu’il s’agit du référencement par entité. C’est pourquoi il vous faut toujours considérer votre site comme un ensemble.
Comment Google utilise-t-il les entités une fois qu’elles sont extraites ?
Google synthétise les informations de manière beaucoup plus précise qu’auparavant. Il est ainsi devenu capable de juger de l’utilité de vos pages vis-à-vis des requêtes en ligne.
Vous ne le savez peut-être pas, mais certaines des plus importantes mises à jour de l’histoire de Google ont (notamment) servi à faire évoluer le moteur de recherche vers un web basé sur les entités.
- Google Hummingbird : Avec cette mise à jour, Google a transformé la manière dont il traitait les requêtes des internautes en passant d’une approche basée sur les mots-clés (chaînes de caractères) à une approche basée sur les entités (objets). Elle a posé les bases de son nouveau process de référencement.
- Google Rankbrain : RankBrain permet à Google de mieux répondre aux requêtes qu’il n’a jamais rencontrées auparavant. Pour ce faire, il utilise des entités et une couche d’intelligence artificielle.
- Google BERT : ce paramètre utilise le traitement du langage naturel (NLP) pour comprendre les requêtes de recherche, interpréter le texte des pages web et ainsi identifier les entités et les relations qui les relient.
Un bon moyen de voir le référencement d’entités en action consiste à rechercher votre célébrité préférée sur Google. En ce moment, la mienne est l’auteur-compositeur-interprète Hozier. J’ai souvent cherché son nom à des fins de recherche personnelle et c’est donc de bonne guerre que je l’utilise pour illustrer cet article. Je suis sûre qu’il ne m’en voudra pas.
Si je fais une recherche sur Hozier, son Knowledge Graph s’affiche comme tel :
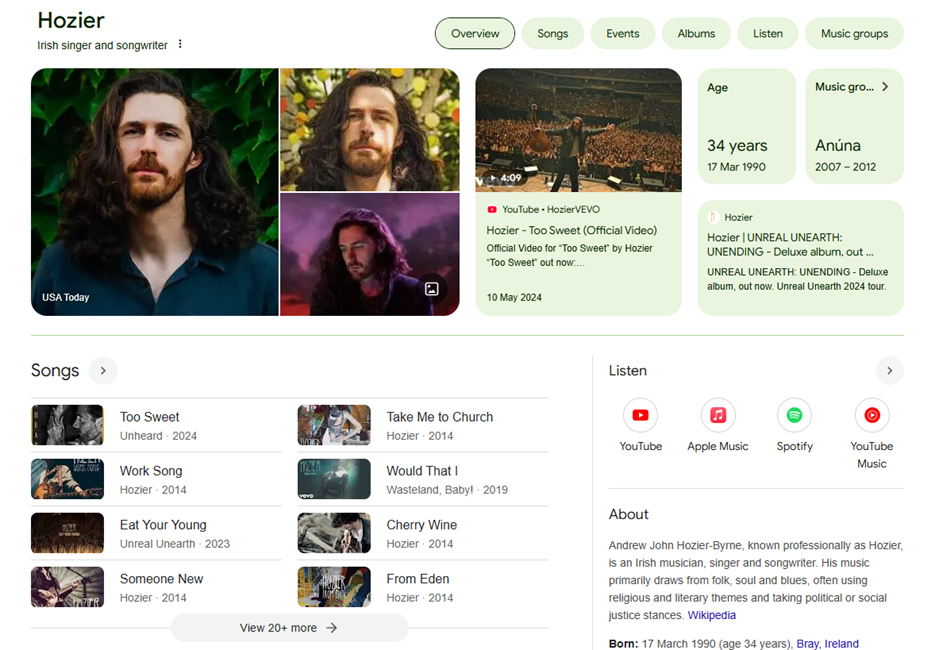
Un « knowledge graph » est une illustration parfaite d’entités en action. En effet d’expérience, Google, connaît à l’avance les principaux sujets que les internautes souhaitent aborder lorsqu’ils recherchent son nom. Alors il les affiche d’office.
- Des photos de lui avec son allure mystérieuse et fantaisiste.
- Chansons
- Evénements
- Albums
- Écouter
- Groupes de musique
Si l’on réfléchit logiquement à la manière dont Google a réussi à savoir tout cela, la SEULE explication logique est une base de données d’entités qui connaît les concepts qui sont sémantiquement proches de cet artiste mystérieux et fantaisiste.
C’est est encore plus évident si vous recherchez une entité connue pour des choses complètement différentes.
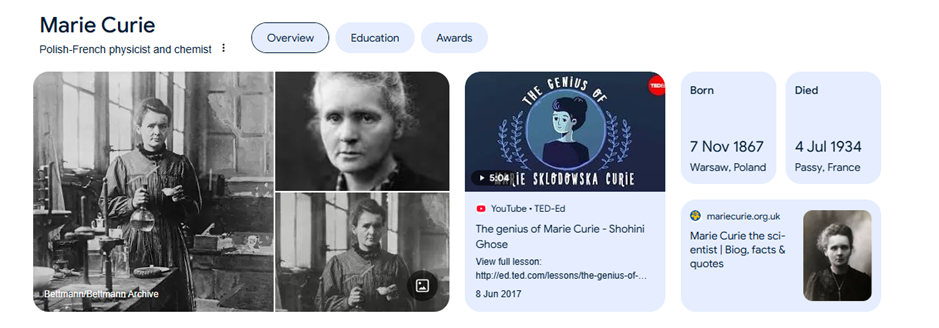
Ici, Google sait d’expérience que les personnes qui font une recherche sur Marie Curie veulent en savoir plus sur sa formation et ses récompenses. Personne n’a jamais écrit ce qui apparaît à l’écran, mais le Knowledge Graph est capable d’extraire et de rendre visibles les entités secondaires ou associées, qui gravitent autour d’une entité principale, en l’occurrence l’immense, mais peu fantaisiste, Marie Curie.
Peut-on aider Google à détecter les entités d’une page ?
Oui, c’est tout à fait possible. Pour ce faire, vous devez intégrer un schéma (balisage) à vos pages. Le schéma est essentiellement du « code qui décrit du code ». Il est là pour désambiguïser les éléments de votre page afin que Google n’ait pas à passer par les trois premières étapes (qui sont sujettes à des erreurs ou à des omissions) pour comprendre de quoi vous parlez.
Il est assez simple de placer un schéma de page web sur une page. Cela ressemble à ça :
| « about »: [ {« @type »: « Thing », « name »: « Google_Knowledge_Graph », « sameAs »: « https://en.wikipedia.org/wiki/Google_Knowledge_Graph »}, {« @type »: « Organization », « name »: « Google », « sameAs »: « https://en.wikipedia.org/wiki/Google »}, {« @type »: « Thing », « name »: « knowledge graph », « sameAs »: « https://en.wikipedia.org/wiki/Knowledge_Graph »}, ], « mentions »: [ {« @type »: « Thing », « name »: « concept », « sameAs »: « https://en.wikipedia.org/wiki/Concept »}, {« @type »: « Thing », « name »: « users », « sameAs »: « https://en.wikipedia.org/wiki/User_(computing) »}, {« @type »: « Thing », « name »: « entities », « sameAs »: « https://en.wikipedia.org/wiki/Named_entity »}, {« @type »: « Thing », « name »: « data », « sameAs »: « https://en.wikipedia.org/wiki/Data »}, {« @type »: « Thing », « name »: « INPUT », « sameAs »: « https://en.wikipedia.org/wiki/Information »}, {« @type »: « Thing », « name »: « result », « sameAs »: « https://en.wikipedia.org/wiki/Result »} ] } </script> |
Il s’agit du schéma présent sur le site https://inlinks.com/knowledge-graph-explained/ où nous nous plongeons à corps perdu dans les subtilités du graphe de connaissances.
Pour venir en aide à Google, ce schéma fait 3 choses :
1. Catégoriser le concept en chose, personne, lieu ou organisation.
- « @type » : « Thing » ; “@type” : « Organization »
2. Définir le mot-clé que vous utilisez.
- « name » : « Google_Knowledge_Graph »,
3. Relier ce mot-clé à quelque chose qui a un KGMID, tel qu’un article de Wikipedia.
- « sameAs » : https://en.wikipedia.org/wiki/Google_Knowledge_Graph
Pas mal, non ? Mine de rien, vous êtes littéralement en train d’expliquer à Google de quoi vous parlez tout en reliant directement votre sujet à une entrée de son Knowledge Graph. Cette méthode permet d’éviter les erreurs ou les mauvaises interprétations et d’économiser de la puissance de traitement lorsqu’il s’agit pour lui d’analyser votre contenu. Vous verrez que l’application de ce schéma à vos pages vous sera d’une très (très) grande utilité.
3. Quels sont les services Google qui utilisent des entités ?
Est-ce une erreur de dire qu’ils le sont tous ? Pas vraiment. D’une manière ou d’une autre, les entités influencent désormais le traitement de base de Google. Elles sont donc là, tapies dans l’ombre, dès que vous faites quelque chose en ligne. Ceci étant dit, examinons quelques exemples plus en détail :
Google Business
Le profil Google Business s’appuie sur la reconnaissance des entités nommées (NER) pour identifier et organiser les informations relatives aux entreprises. Chaque entreprise est traitée comme une entité distincte dotée d’attributs tels que son nom, son emplacement, sa catégorie et ses services. Cela permet à Google de comprendre ce que l’entreprise propose et de l’associer à des requêtes de recherche pertinentes.
Par exemple, si un utilisateur recherche « Joe’s Pizza », Google reconnaît qu’il s’agit d’une entité unique et la relie à des données connexes connues telles que l’adresse, les heures d’ouverture, les commentaires et les entreprises similaires. Lorsque les utilisateurs effectuent une recherche plus large, comme « restaurants italiens à New York », le NER aide Google à faire correspondre la requête aux entreprises de cette catégorie et de cette zone géographique. Google utilise également des entités pour analyser les avis, en extrayant des informations telles que « excellent service » ou « livraison lente » et en les mettant en évidence pour les utilisateurs.
Ces connexions font partie du Knowledge Graph de Google, qui relie aussi les entreprises à des lieux, à des secteurs et même à des concurrents, ce qui permet d’enrichir encore un peu plus les résultats de recherche.
En outre, le NER joue un rôle important dans les recherches vocales et les requêtes locales. Si quelqu’un demande : « Quelle est la meilleure boulangerie près de chez moi ? » Google reconnaît le terme « boulangerie » comme une entité et trouve les entreprises correspondantes à proximité. Cette même technologie prend en charge les annonces personnalisées, en veillant à ce que les supposées « meilleures » entreprises soient présentées aux utilisateurs qui recherchent leurs services.
En s’appuyant sur la reconnaissance des entités, Google permet donc aux internautes de trouver plus facilement des entreprises et d’interagir avec elles, ce qui améliore à la fois les résultats de recherche et l’expérience globale.
Google Maps
Google Maps utilise la reconnaissance d’entités nommées (NER) pour identifier et comprendre les noms de lieux, d’entreprises et de points de repère dans les requêtes des utilisateurs. Par exemple, lorsque quelqu’un recherche « Starbucks près de Central Park », Google Maps reconnaît « Starbucks » comme une entreprise et « Central Park » comme un point de repère. Cela permet de fournir des résultats de recherche et des itinéraires précis.
La NER joue également un rôle dans la conversion des noms de lieux en coordonnées géographiques (géocodage) ou dans la transformation des coordonnées en noms (géocodage inversé). Si vous tapez « Tour Eiffel », Google Maps l’identifie comme un point de repère et la localise sur la carte. De même, lorsque vous déposez une épingle, Google Maps peut déterminer le lieu nommé le plus proche.
En identifiant et en classant ces entités, Google Maps permet aux utilisateurs d’obtenir des résultats précis et adaptés au contexte de la navigation, les informations sur les entreprises locales et les recherches de lieux.
Google Discover
Google Discover est un flux de contenu personnalisé qui recommande des articles, des vidéos et d’autres médias en fonction de vos centres d’intérêt, de votre historique de recherche et de votre activité, bref de votre profil en ligne. Il utilise la reconnaissance des entités nommées (NER) et une technique de traitement du langage naturel (NLP), pour améliorer les recommandations :
1. Comprendre le contenu : La reconnaissance d’entités nommées identifie des entités clés telles que des personnes, des lieux ou des organisations dans des articles, ce qui aide Google à classer les sujets.
2. Cartographier les intérêts de l’utilisateur : Il suit les entités dans vos recherches (par exemple, « Wicked (2024) ») afin d’aligner les recommandations sur vos préférences.
3. Regrouper des sujets : La NER regroupe les contenus connexes sous des thèmes plus larges, comme l’association de « AI » avec « OpenAI ».
4. Améliorer la précision : il résout les ambiguïtés (par exemple, « A4 » en tant qu’autoroute, format papier ou modèle de voiture) pour garantir la pertinence du contenu.
La NER permet à Google Discover de fournir des recommandations plus pertinentes et plus attrayantes.
4. Comment le référencement d’entités peut-il augmenter vos revenus en ligne ?
L’optimisation de votre site web ou de celui de votre client en prêtant attention aux entités auxquelles Google vous associera est être la mesure la plus rentable que vous pourriez prendre dans les prochains jours. Google traite déjà votre contenu par le biais d’entités, comme nous l’avons expliqué plus haut. L’optimisation de ce traitement ne peut donc être qu’un atout supplémentaire.
Décomposons le processus en plusieurs étapes :
La stratégie
Étape 1 : Extraction d’entités
La première chose à faire est de trouver la page Wikipédia (et donc l’entité) qui décrit le mieux l’entreprise que vous essayez d’optimiser. Si vous êtes plombier généraliste, choisissez plomberie, mais si vous êtes spécialisé dans la recherche de fuite, adopter cette entité plus spécifique. Ensuite, je vous encourage à utiliser un outil de reconnaissance d’entités pour extraire les informations qui entourent votre entité principale.
S’il s’agit d’InLinks, le résultat sera le graphe de connaissances de votre site web.
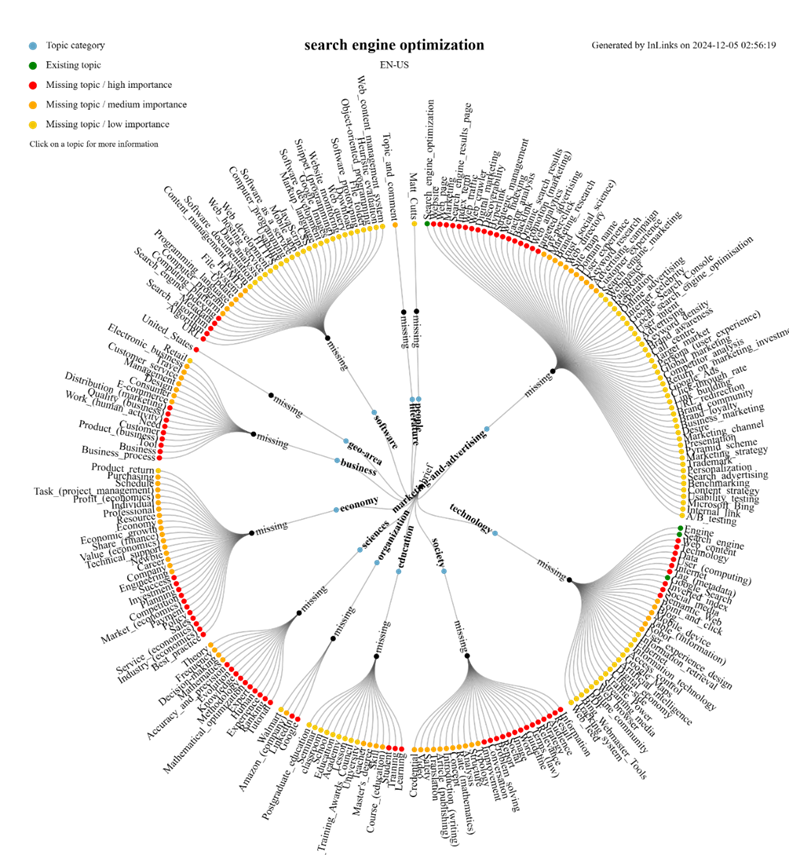
Voici le plan localisé de toutes les sous-entités qui entourent l’entité que vous avez définie comme étant principale, en l’occurrence ici, le terme SEO. Elles sont classées en fonction de leur « importance » ou de leur pertinence. Je sais que cela semble représenter beaucoup de travail, mais vous devez vous efforcer de couvrir par du contenu original toutes les entités les plus importantes de ce graphique sur l’ensemble de votre site web. Considérez cela comme étant la base d’un plan de contenu performant.
Étant donné qu’il faut que Google vous considère comme un spécialiste des entités dont vous parlez et qu’il vous classera en fonction du sérieux avec lequel vous les traitez, il est important de vous consacrer d’abord aux entités signalées en rouge (entités manquantes).
Cela nous amène à la notion de groupes d’entités car il ne suffit pas de mentionner des entités pour que l’affaire soit conclue. Vous devez approfondir le traitement chaque entité comme si vous étiez un spécialiste de votre sujet. Élargir le contexte dans lequel évoluent vos entités s’appelle aborder un groupe de sujets. Cela revient à accroître votre réputation d’expert.
Étape 2 : Développer les groupes de sujets
Vous avez donc effectué votre recherche d’entités, vous avez obtenu votre graphe de connaissances localisé et vous devez maintenant rédiger le contenu autour de chaque entité. Pour ce faire, commencez à développer votre contenu sur ces entités dans différentes directions afin de montrer l’étendue et la profondeur de vos connaissances et, au final, l’autorité que vous avez sur le sujet.
InLinks aborde cette question grâce à son outil Topic Planner. L’idée principale est de prendre 2-3 de vos entités les plus importantes (et par là, j’entends les 2-3 entités qui pourraient résumer la thématique de votre site) et de les développer avec, pour point référence de départ, le contenu de vos concurrents. Cela signifie qu’il faut déterminer, à l’aide de l’outil, les groupes de sujets pertinents. Vous pouvez voir cet outil en action ici en image…
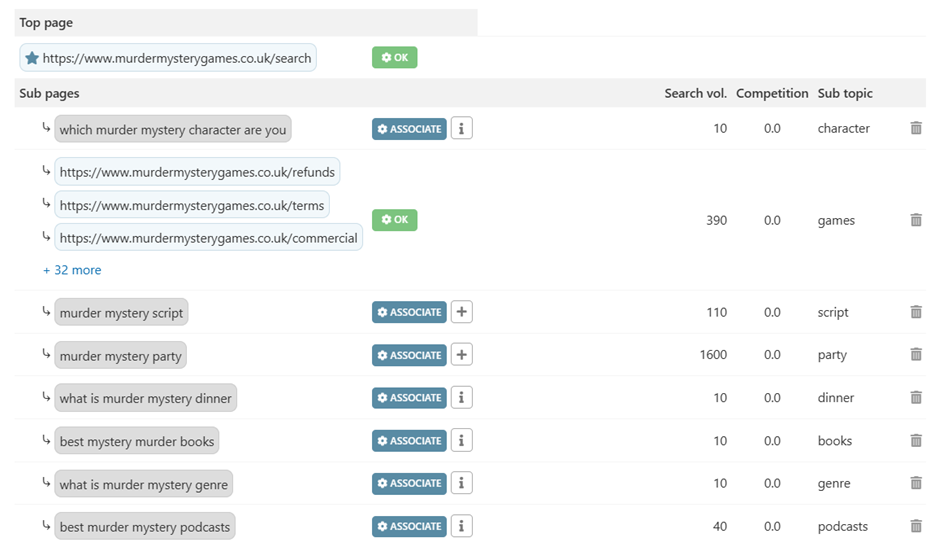
… et là, en vidéo : https://youtu.be/_5Re_2CAiFo
Une fois que vous avez créé le contenu, il vous faut trouver le moyen de démontrer à Google qu’il figure dans un contexte bien plus large que la simple page qui le contient, en reliant celle-ci aux autres pages connexes de votre site. Pour ce faire et ainsi obtenir une augmentation du trafic, vous devez adopter une stratégie de maillage interne basée sur… les entités.
Étape 3 : Optimiser vos liens internes pour les entités
Je ne m’étendrai pas trop sur les tenants et les aboutissants des liens internes basés sur les entités ici, car le sujet nécessite à lui seul son propre guide (que nous avons d’ailleurs déjà écrit). L’idée principale est qu’il faut démontrer votre autorité en déployant des liens internes qui pointent et connectent l’ensemble de votre site autour des principales entités qui le structurent.
Voici un aperçu rapide de la manière dont vous devez procéder :
1. Choisissez une page, si possible autoritaire, centrée sur l’entité qui vous intéresse.
Évitez de créer plusieurs pages ciblant la même entité afin d’écarter tout risque de confusion ou de cannibalisation de la part des moteurs de recherche.
2. Identifier les possibilités de texte d’ancrage
Recherchez les mentions de l’entité sur votre site web à l’aide d’outils tels que la commande « site : » de Google ou les fonctions de recherche interne.
3. Ajouter des liens naturels
Reliez les mentions de l’entité à la page ciblée en utilisant un texte d’ancrage naturel et pertinent. Par exemple, dans le cadre d’un site sur le jardinage, liez « taille» à « haie » « vigne » ou « rosier » en fonction du contexte.
4. Inclure des synonymes et des termes apparentés
Utilisez des variantes ou des termes apparentés (par exemple, liez « programmateur», « goutteur » ou « asperseur » à une page dédiée à l’arrosage automatique) afin d’améliorer le référencement et la pertinence des liens.
Cette stratégie permet de créer une structure claire, adaptée au référencement, qui met en valeur le contenu correspondant à l’entité qui vous intéresse et en accroît la visibilité.
Les résultats
L’avantage de cette stratégie est qu’elle est tout aussi efficace pour les petites entreprises que pour les grandes. Voici un exemple d’un client qui a mis en œuvre le référencement par entité :
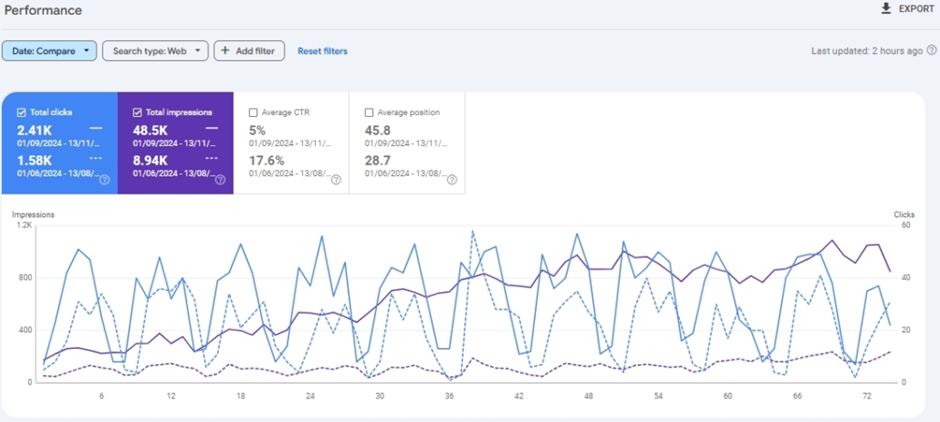
Pour en savoir plus sur cette étude de cas, cliquez ici : https://inlinks.com/case-studies/case-study-440-in-impressions-and-52-in-clicks-3-months-after-using-inlinks/.
Comment devenir une entité dans le Knowledge Graph de Google ?
Au sens propre, tout le monde est une entité. Malheureusement, d’un point de vue technique, seules les personnes ayant un KGMID le sont aux yeux de Google. Devenir une entité à part entière dans une base de données n’est pas chose aisée et exige que vous ayez une page Wikipédia écrite à votre sujet. Pour cela, évidemment, le mieux est d’avoir battu le record du monde du 100m, d’avoir été élu président de la République ou de trouver un remède contre le cancer… Si ce n’est pas votre cas, tout n’est pas perdu, car vous pouvez avoir une présence sur le web sans pour autant être une entité. Jetons un coup d’œil à ce que j’aime appeler les « entités sans identité ».
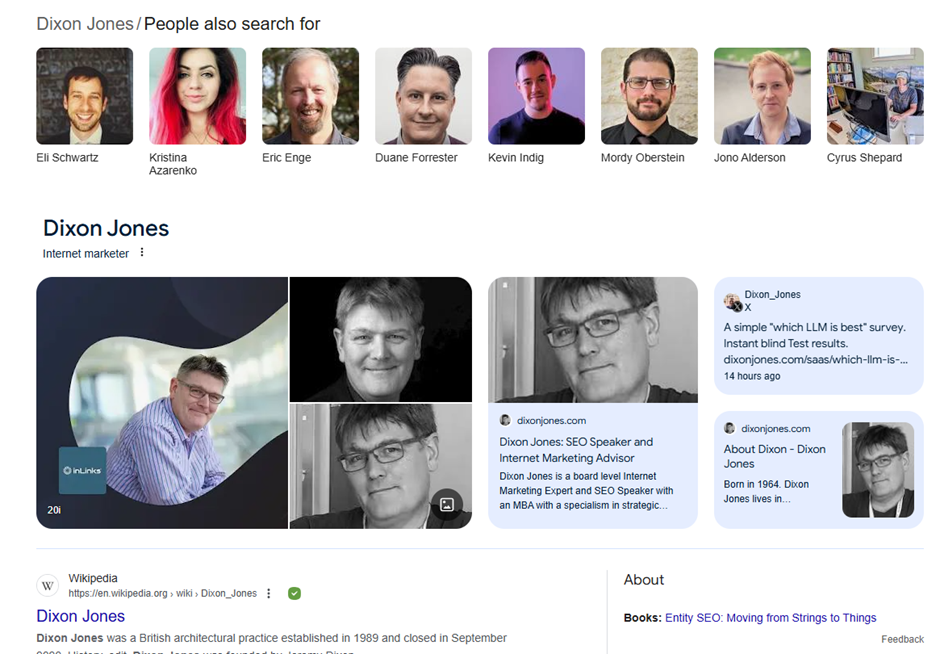
Lorsque vous recherchez Dixon Jones, notre vénérable PDG, un graphe de connaissances apparaît, et pourtant, il n’a pas, à notre connaissance, de KGMID. Homonymie oblige, la page Wikipédia qui lui est associée en dessous correspond à une entité totalement distincte, qui n’est même pas humaine, à savoir un cabinet d’architecture. En outre, d’autres personnalités du secteur seront également suggérées, avec, luxe suprême, leur photo de profil.
Cela suggère que, bien que les informations soient extraites par le biais des graphes de connaissances, les KG ont également la capacité de créer, le temps de répondre à une requête, de nouvelles entités vides à partir de l’inférence. Ils peuvent le faire par le biais de profils de médias sociaux et d’une empreinte numérique plus large. Bien que l’entité Dixon Jones n’existe officiellement pas, elle est si fortement associée aux entités qui ont un KGMID qu’il y a suffisamment d’informations pour créer ex nihilo le panneau de connaissances correspondant.
Mon principal conseil à ceux qui cherchent à devenir une entité sans ID est donc de continuer activement à publier et à renforcer leur proximité sémantique avec l’entité ou l’industrie souhaitée.
Comment votre entreprise peut-elle devenir une entité dans le Knowledge Graph de Google ?
Les entités commerciales sont un peu plus accessibles que les entités personnelles. Je pense que l’une des principales raisons à cela est CrunchBase. En effet, les entreprises enregistrées disposent généralement d’une entité CrunchBase. Certes, cette entité n’est pas aussi puissante qu’une entité Wikipédia, mais ouvrez grand vous yeux…
Dans ce profil, InLinks est catégorisé comme une « organisation » dans l’URL et les informations ont été complétées manuellement. Bien que je n’aie aucune preuve empirique suggérant que c’est un atout pour le référencement, je pense que le fait d’établir un lien vers cette catégorie dans le schéma de vos pages contribue grandement à désambiguïser votre entreprise. Pour InLinks, cela donnerait ceci :
{« @type » : « Organization », “name” : « InLinks », “sameAs” : “https://www.crunchbase.com/organization/inlinks”}
5. Entités, LLM et IA
Dans cette nouvelle ère de la recherche où presque tout comporte un élément d’intelligence artificielle, il pourrait sembler inutile d’optimiser son site. Cette impression est renforcée par la fausse croyance selon laquelle les outils d’intelligence artificielle tels que Google Gemini et ChatGPT ont été formés à partir d’informations qui sont désormais statiques, ce qui signifie que leur savoir est un acquis à partir duquel les modifications se font à la marge. En fait, ce n’est pas du tout le cas, et la façon d’optimiser votre site pour servir l’IA est de prêter attention aux entités.
Il est vrai que l’IA ne parcourt pas directement le web pour faire ses déductions. En réalité, elle parcourt plutôt les index des moteurs de recherche et utilise différentes API pour trouver des informations.
À ce sujet, j’ai demandé à ChatGPT comment il procédait, et il m’a très gentiment répondu :
« Lorsque j’effectue une recherche sur le web, je ne parcours pas directement le web comme le fait un moteur de recherche. Au lieu de cela, j’interroge l’index d’un moteur de recherche ou j’utilise des API pour recueillir des informations pertinentes et actualisées. Voici un aperçu simplifié du processus :
1. Analyse de la requête de l’utilisateur :
a) J’analyse votre question ou votre demande pour déterminer les termes clés et le contexte.
b) Par exemple, si vous demandez : « Quel temps fait-il à Paris ? » j’identifie « météo » et « Paris » comme des éléments clés.
2. Formulation de la requête :
a) Sur la base de l’analyse, j’élabore une requête qui comprend les mots ou expressions clés pertinents.
b) Je détermine également si votre requête bénéficie d’un contexte supplémentaire, tel que le lieu, l’heure ou des sources spécifiques.
3. Requête au moteur de recherche :
a) J’envoie la requête à un moteur de recherche ou à une API spécifique pour récupérer les résultats. Cette étape consiste à exploiter les données existantes du moteur de recherche qui ont déjà été explorées et indexées.
4. Récupération des résultats :
a) J’analyse les résultats fournis par le moteur de recherche, en me concentrant sur les sources de haute qualité et de bonne réputation.
b) En fonction de la tâche, je peux donner la priorité à certains types d’informations (par exemple, des réponses sommaires, des guides détaillés, des informations sur les entreprises locales, etc.)
5. Synthèse et réponse :
a) J’extrais les informations les plus pertinentes des résultats et je les présente sous une forme concise et conviviale.
b) Si nécessaire, je fournis des liens vers les sources pour plus de transparence et d’exploration. »
Il y a deux étapes qui ressortent vraiment dans le contexte des entités : la 1 et la 5. La reconnaissance des entités nommées est utilisée pour comprendre le contexte dans lequel une requête est posée. Elle doit identifier l’entité et relier ce qu’elle signifie à une de base de données d’entités. Celle-ci peut ensuite être utilisée pour extraire les meilleurs résultats de recherche. Les résultats sont ensuite analysés plus en détail lors de l’étape de synthèse et de réponse par le biais d’une NER encore plus poussée.
Je vais écrire un article à part entière sur ce sujet, mais pour résumer, il est clair qu’on ne peut pas optimiser un site directement pour l’IA sans l’optimiser d’abord pour les moteurs de recherche. Et la clé de ces deux actions est… l’entité.
Conclusion
Le référencement par les entités est plus qu’une simple notion à la mode. C’est désormais une approche qui change la donne pour se connecter à son public et se démarquer dans un paysage numérique encombré. En comprenant comment les moteurs de recherche interprètent les entités et en exploitant des outils tels que le Knowledge Graph et les services NLP de Google, vous pouvez créer un contenu qui se classe mieux, qui a une résonance plus profonde et qui produit des résultats concrets.
Les stratégies présentées dans ce guide sont conçues pour vous aider à dépasser les mots-clés et à entrer dans un monde où le sens et le contexte règnent en maîtres. En mettant en œuvre ces techniques, vous améliorerez non seulement votre visibilité, mais vous transformerez également vos efforts de référencement en un investissement rentable à long terme.
Il est maintenant temps de mettre ces idées en pratique et de voir la différence que le référencement d’entités peut apporter à votre entreprise.
Texte original de Genie Jones – Relu et validé par Dixon Jones – Traduit par Benoit Charbonneau



Laisser un commentaire
Rejoindre la discussion?N’hésitez pas à contribuer !