InLinks just added the concept of “Search Engine Understanding” (SEU) to its content Optimization audits, so it seems good to explain this concept.
What is SEU?
SEU or “Search Engine Understanding” is an analysis of the engine’s natural language processing API’s ability to recognize all the entities or topics on a page of content. Modern search engines (in particular, Google) have moved towards this approach of connecting a page’s underlying concepts to their knowledge graph. However, parsing words and text and trying to extract underlying concepts is not always an exact science. InLinks publishes regular case studies tracking Google’s understanding of concepts in different sectors, according to its own natural language API.
How do you Calculate SEU?
Calculating SEU is done by comparing two different NLP (Natural Language Processing) algorithms. The first is Google’s public Natural Language API and the second is Inlinks’ own proprietory NLP API which is not currently public. We then look at the number of defined entities in both data sets to get a percentage score of how many Google registers in its API.
How Good is the inLinks NLP API?
The InLinks API is specifically designed to be overly aggressive at extracting entities from a corpus of text. This will occassionally mean that it finds topics that a human would say are incorrect (for example, we might see text talking about an “engine” in this text and incorrectly associate this with a combustion engine). This aggressive approach is important, however, for SEOs, because it is the job of the content optimizer to match genuine topics to the about schema and to help ensure the CORRECT entities are communicated to Google. (InLinks also helps automate this through about schema)
Does Google use the same API in its search engine as they offer Publicly?
We only know that the one we use is the official Google API. It is part of the larger Cloud Machine Learning API family from Google.
Why is SEU helpful for SEOs and how do I use it?
If you can rephrase your content to make it easier for a search engine to extract the correct topics as relevant and meaningful, then the search engine can store all those topics very efficiently in their Knowledge Graph. When a user asks for a particular search query, a Search engine can look at the pattern of topics that might be relevant for answering that query and then display results with a close digital footprint to the one the searcher may need.
Should I be aiming for 100%?
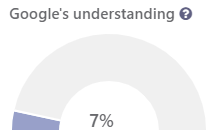
No, not really. Our Natural Language Understanding case studies are showing that the best of breed sites are on average only scoring around 18% at the time of writing, although this varies quite significantly by sector. In the education sector, for example, Genie Jones at Warwick university spotted that in the education sector, machine learning is significantly better at 34% and might even be doing its part to help widen participation to higher education. On the other hand, dumbing down your text just to help a “dumb search engine” might also be having a negative bias on humanity. It is a complex topic that I will enjoy philosophizing over for years to come. (Keynote opportunity, anyone?)



This looks very interesting – I will try it and see what the results are 🙂
how to improve the score
One way to improve search engine understanding may be to check the grammar. Natural Language Processing understands content netter when the context is clear. I am a big fan of Grammarly, these days. It is a desktop application that corrects grammer.
Dixon,
Does schema and its application influence the SEU of a web page?
It might. Indeed, it SHOULD but we have no documentation on Google’s site on “About” schema. The logic is that by using the schema to connect the content to the entity, Google should be able to then recognize it. However – I do not believe Google is using their publicly available NLP API in their own index. Their API does not seem to return enough entities. But I am happy to be proved wrong either wy. Our SEU can only compare our results with the entities recognized in Google public API.
I have seen decent results by using CollectionPage schema, running the content through an NER and using the extracted entities in either the “About” or “Mentions” properties of the CollectionPage. Typically using either the Wikipedia URI or DbPedia URI. It should be noted as well that BERT has a hard time tokenizing long content. So, making sure the content is clear and straight to the point could be something to keep in mind. Oh and also I 100% agree about the grammar. I have been using Hemingway to fix grammatical errors and believe that has helped but the test set was pretty small.
You said: >>So, making sure the content is clear and straight to the point could be something to keep in mind<< I think that makes sense, so the inLInks content audits also add the Flesch-Kinkcaid Readability score, as well as our SEU score. The only sad thing is that we are dumbing down human understanding whilst the machines catch up.
What role, if any, does images play in crafting the SEU of a page?
We don’t use images in this. We would, however, use image captions, if they exist. I don’t know if we use Alt text.
how to improve the SEO score of SEO unerstanding?
Improving the SEU score, you mean? The jusry is still out as to whether you would even want to… but one way would be to shorten the article and only talk about the entities Google already understands. Another is ato start mentioning brands (which Google usually understands), but I don’t think this will really be goos for SEO… manipulatinfg SEU isd a bit like manipulating Moz’s Domain Authority… is is a KPI, not a target… if you start to manipulate the foundation on which yoiu are c=scoring yourself, you actually undermine your own efforts. Infact… I feel a blog post coming on about that! 🙂
Would you say then, that we should just primarily focus on the important missing topic(s) when it comes to our content? Since SEU may be something ‘manipulative’ ?
Yes. What we are working on now is trying to work out when you should be adding content/topics into an existing page and when you are b etter off starting a new article. That’s a toughie, but Fred is making headway. Of course, when there IS no missing content (ie you have covered it all) you will still need to do something else if you are not ranking… we don’t have all the answers. The problem at the moment with SEU though, is that very LONG articles just keep adding topics in our own entity extraction algorithim, so they tend to end up with lower SEU scores. AS with every SEO metric made by a team outside Google, there are limits to what it can say and I think we could do better if there is a real appetite for it.
Leave a Reply
Want to join the discussion?Feel free to contribute!