
After listening to lots of feedback from our users, we are now solving the problem of needing to manually add pages that have gone live after you’re first install. We are now pleased to announce that our new feature allows you to configure your project settings. Now you can:
- Add pages automatically via RSS
- Give projects convenient labels/names
- Modify our bot’s crawl behaviour to exclude a footer.
Please note that these features are still in Beta, so tell us if you find a bug. But here’s everything you need to know.
Automatically add new pages via RSS.
Some users want new pages to be automatically added to their projects as soon as they are created. However, since adding a page costs a “credit” and because you ultimately pay based on the number of pages you have in the system, we understand that this should be optional, not automatic. So, we have now solved this paradox by letting you choose the behaviour on a project-by-project basis. By giving us the RSS feed URL for your site, we can check regularly to see if new pages have been added to the site. If they have, then you can have them automatically imported and crawled.
Where can I find the automatic RSS recrawl?
The new feature can be found on your main dashboard. This is where we differentiate all of your projects. Here’s a quick overview of mine:
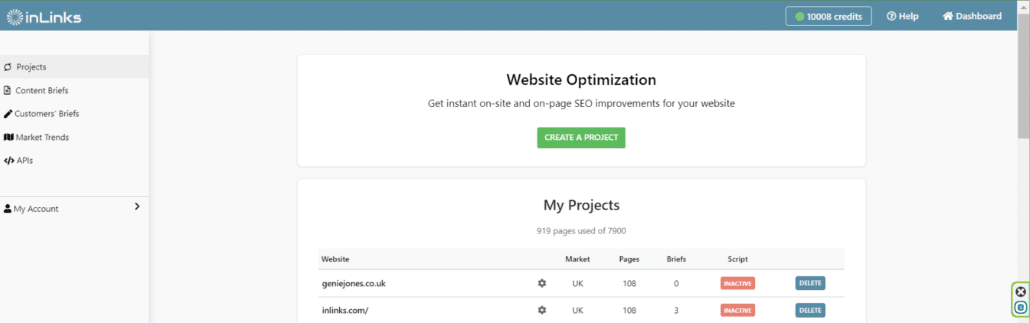
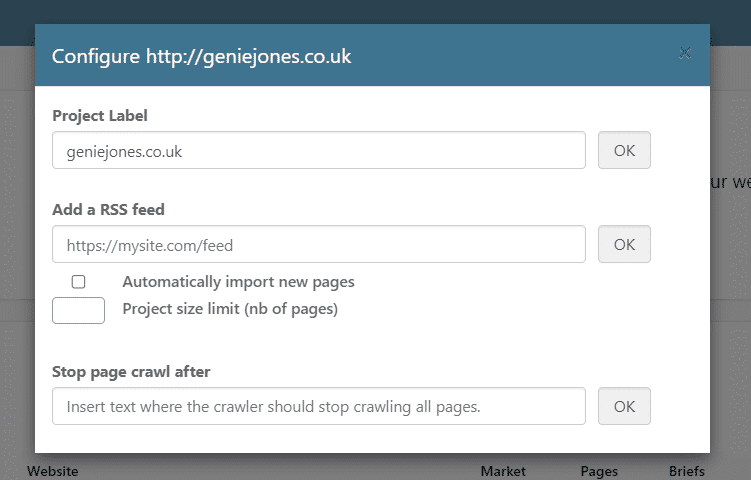
Notice the small cog next to the project name? Give that a click, and you will find this:
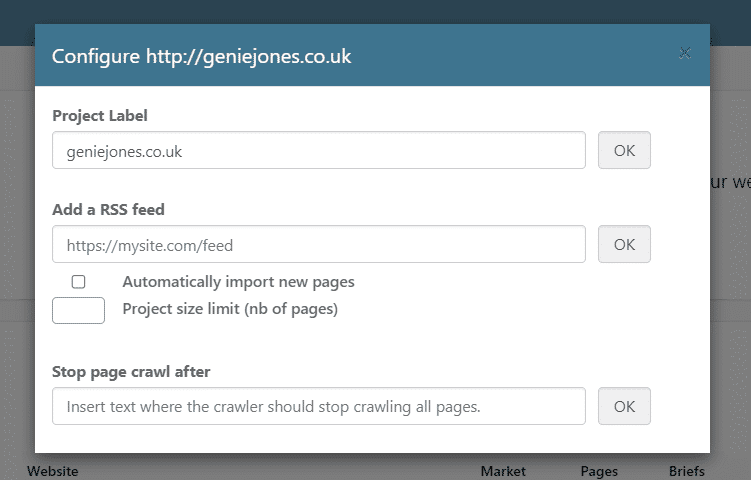
From this tab, you now not only have the ability to rename/label a project away from its original name, but you also have the ability to add an RSS feed plus some critical parameters for crawling.
Finding your RSS feed URL
Most WordPress blogs have an RSS feed at Yourdomain.com/blog/feed (or yourdomain.com/feed id the whole site is WordPress). You should see a page that is text-based and looks a bit like ours:
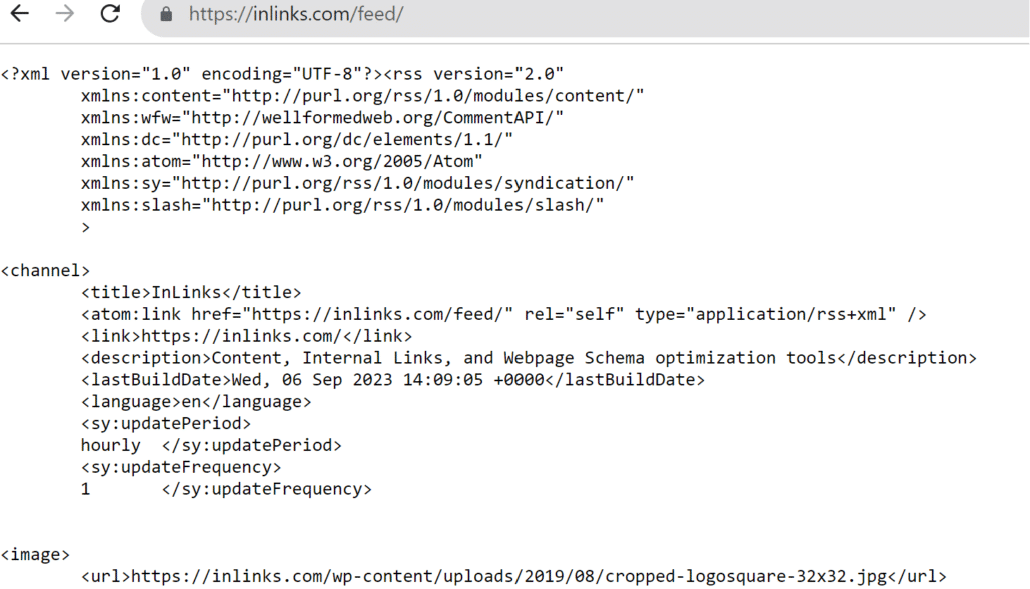
If /feed does not look right, try /RSS. Not all websites have RSS feeds. If you cannot find the URL, you may need to ask your host or a developer for this.
What does adding an RSS feed actually do?
By adding an RSS feed, Inlinks will automatically bring in pages it finds without you having to manually re-add pages. We have added the option to set a limit underneath to make sure we do not keep adding pages infinitely if you are trying to keep your account size down. Give it a go, and let the stress of keeping your projects up to date fade away!
Every time you publish a new post, InLinks will bring it into your account and sort out the internal linking for you based on the targeting you have already done.
Rename your Project
We were finding that some projects were actually based on the same website but just in different sections. So now you can give your projects handy memorable names by rebalelling them.
Why is renaming a project useful?
It can be helpful for many reasons. If you have one large website written in multiple languages, you may want to create separate projects with the same URL but rename them as
Geniejones.co.uk ENGLISH
Geniejones.co.uk FRENCH
Etc…
It is also useful when you want to create a project that may not yet exist. To see more on this, head to my video on creating an entire website from scratch! :
https://www.linkedin.com/embed/feed/update/urn:li:ugcPost:7105883369816674304?compact=1
Modify the Crawl Behaviour of our Bot on your Projects
This has been a much-requested feature. Being able to stop the crawler after a certain piece of text is something that we have been able to do for individual projects via the support, but now customers can set this control up directly.
What does stopping the page crawl after a specific phrase really accomplish?
At the bottom of that screen, we allow you the ability to stop bringing text from a page after a certain phrase. This is so we do not keep bringing text from the footer of your site or potential reoccurring review text. Let’s look at a quick example.
At the bottom of every page in the inlinks suite is this footer text:

I don’t really need inlinks to create internal links from this area on our website, and the terms and conditions really shouldn’t be crawled.
So I would add the parameter ‘Let’s Talk!’ into >>stop page crawl after<< to ensure inlinks doesn’t read this part.
It really is that simple!
Thanks for stopping into this update, and, as always, our team is on hand to handle any questions you may have through a demo.



Leave a Reply
Want to join the discussion?Feel free to contribute!