
Le Graphe des Connaissances Expliqué
Techniquement parlant, le graphique de connaissance de Google alias le fameux « Google Knowledge Graph » est


Techniquement parlant, le graphique de connaissance de Google alias le fameux « Google Knowledge Graph » est
Devenir une entité ou l’expert d’une entité Votre première décision stratégique est de savoir si
Être (ou ne pas être) une entité Si vous êtes une entreprise ou une organisation,
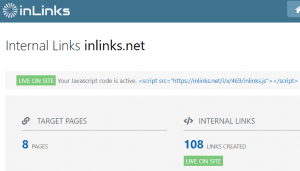
Une structure de liens internes bien conçue améliore considérablement vos chances de voir votre contenu

Qu’est une entité (et ce qui ne l’est pas) En tapant site:exemple.com dans la recherche
Lors de mes recherches sur la mise à jour du Knowledge Graph, il m’a fallu

Réussir à obtenir une entrée dans Wikipédia relève à la fois du parcours du combattant
C’est beaucoup plus difficile qu’il n’y paraît, principalement parce que les entreprises ne sont jamais
Vous pouvez définir vos propres entités sur vos pages web. Lorsqu’un moteur de recherche tel
idée du « marketing de contenu », qui consiste à écrire du contenu sur un sujet en


