
Lors de mes recherches sur la mise à jour du Knowledge Graph, il m’a fallu beaucoup de temps pour réussir à trouver des entités qui n’étaient pas des sujets dans Wikipédia. Il s’avère en réalité que Google dispose d’un grand nombre de données qu’il ne révèlent pas initialement dans la boîte de réponse du graphe de connaissances.
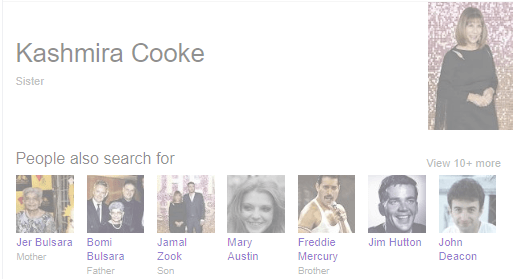
Le graphique des connaissances de Google extrait les informations recueillies à partir de sa base de données. En voici un exemple :
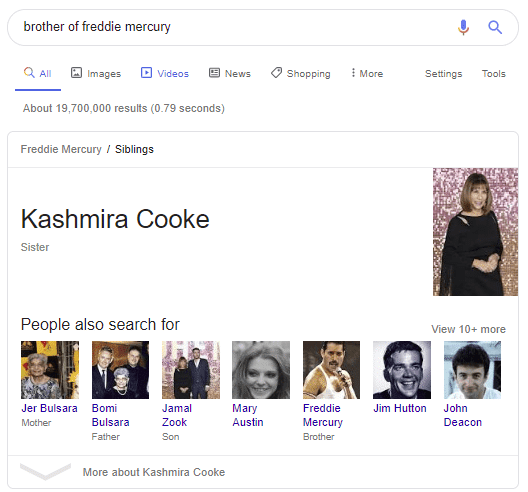
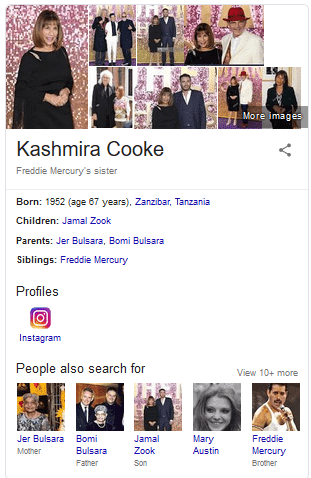
Sous mes yeux ébahis, Google avait fait deux démonstrations de force. Tout d’abord, en ce qui concerne l’objet de la recherche. J’ai cherché « frère » et Google m’a renvoyé une sœur ! Google sait que les termes « frère », « sœur » et « fratrie » sont sémantiquement si proches qu’il a effectué la substitution à ma place (sans même m’en avertir, le coquin…). Deuxièmement, Google a fourni des informations sur une personne qui n’a pas de page Wikipédia.
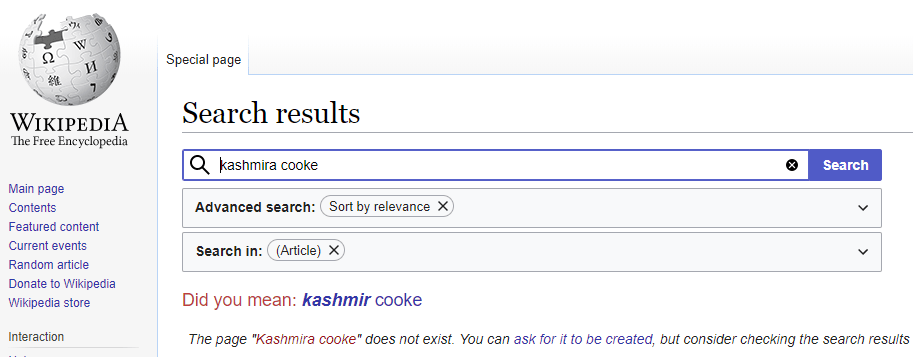
En effet, il n’existe pas d’entité spécifique pour « Kasmira Cooke » dans l’ensemble des sites Wikimedia, si nous utilisons « Wikidata.org » comme mesure :
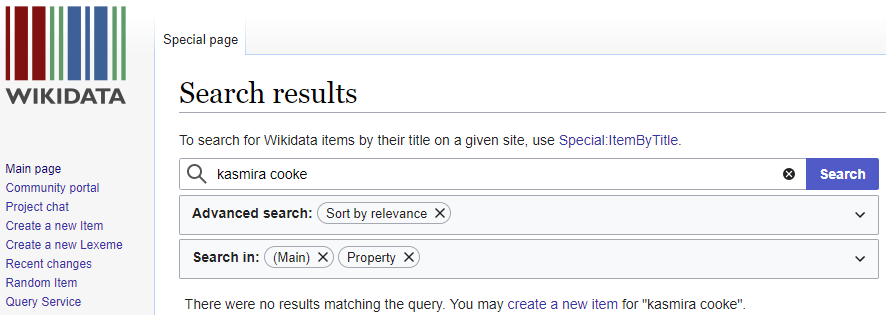
Comment Google est-il parvenu à ce niveau de réflexion et de déduction? Nous avons vu que Google utilise le contenu pour compléter les entrées existantes et, ce faisant, il crée de nouvelles relations. Chaque « triplet », tel que décrit dans une section précédente, crée deux entités. Dans ce cas, Google a estimé qu’il pouvait faire confiance au contenu de Wikipédia, qui fournit plusieurs triplets dans cette seule section :

Après lecture de ce court article, Google sait désormais que :
- Freddie Mercury (est le frère de) Kasmira Bulsara
- Kashmira Bulsara (est un type de) Personne
- Kashmira Bulsara (est la même personne que) Kasmira Cooke
Dès lors Google peut s’atteler à collecter des informations sur la nouvelle entité qu’il a détecté. Entrez « Kasmira Cooke » dans Google et vous obtiendrez une boîte de connaissances assez solide.
Qu’est-ce que cela apprend aux consultants SEO ?
Il n’est pas nécessaire d’avoir une page Wikipédia pour obtenir sa propre entité dans le Knowledge Graph de Google. Néanmoins, il est très utile d’être lié (dans le cas qui nous intéresse, littéralement) à une entité existant dans Wikipédia. Réfléchissez bien à l’entité que vous aimeriez voir figurer dans le Knowledge Graph de Google. A-t-elle des liens étroits avec des listes de Wikipédia ? A-t-elle un frère, une sœur, un père ou une mère célèbre ? Si c’est le cas, votre « entité candidate » pourrait déjà être répertoriée dans Wikipédia comme étant liée à une entité existante. À partir de là, elle obtiendra sa propre entité. Ensuite, vous pouvez éventuellement utiliser le schéma pour aider Google à comprendre que l’entité que vous souhaitez faire figurer dans la liste découle de l’entité déjà présente sur Wikipedia.
Engager un président ou un mécène
Bien sûr, nous n’avons pas tous la chance d’avoir un frère ou une sœur célèbre. Cela dit, la princesse Anne a neuf pages d’associations caritatives qu’elle soutient avec ferveur. Ces pages permettent à Google de faire des liens, bien que cela ne soit jamais garanti. Leuchie Forever Fund est une organisation caritative soutenue par la Princesse Royale, mais à la date de la rédaction de cet article, cette organisation caritative n’avait pas d’entité. Voilà qui offre une voie potentielle à développer pour le référenceur entreprenant.
Adoptez un nom unique pour singulariser votre entité
Google aurait eu beaucoup plus de difficultés à établir cette relation frère-soeur si Freddie Mercury n’était pas un nom unique et si son nom de famille n’était pas « Bulsara ». L’unicité aide le Kwnoledge Graph à atteindre plus rapidement des niveaux de confiance. Je ne suggère pas qu’un changement de nom garantisse le succès, mais il peut être envisagé comme un facilitateur si vous débutez et que vous n’avez pas encore arrêté de stratégie.
Google est un homme blanc agnostique
Cela peut prêter à controverse, mais les mots « frère » et « sœur » ont tous deux des significations différentes dans les communautés noires ou religieuses. Google a tellement associé ces mots à la notion de « fratrie » que son algorithme s’est sans doute un peu trop fermé aux autres interprétations possibles. Cela pourrait provenir du type de personnes impliquées dans l’élaboration des textes servant de références. Ce biais est un problème bien connu dans la construction des graphes de connaissances.
Il existe bien entendu d’autres bases de données que Google prend en compte en plus de Wikipédia… Examinons quelques approches pour qui permettent d’y accéder…
| Page précédente | Guide du SEO sémantique | Page suivante |
Laisser un commentaire
Rejoindre la discussion?N’hésitez pas à contribuer !