
L’évolution de la recherche sémantique
Les moteurs de recherche modernes permettent d’obtenir instantanément des informations à partir de plusieurs documents. Au fil des ans, les systèmes de classification ont évolué vers des résultats de recherche de type « 10 liens bleus » et sont maintenant passés à un format plus encyclopédique. D’une certaine manière, il semble qu’on ait fait le tour de la question.
De l’annuaire à la recherche sémantique
Du temps béni où nous fréquentions davantage les bibliothèques du monde réel (notons qu’elles existent toujours, et que ce sont des lieux de travail toujours très paisibles encore aujourd’hui, pourvu que l’on se tienne à l’écart de la section jeunesse), comment la bibliothécaire faisait-elle pour savoir où se trouvait le livre qu’on lui demandait ? Elle disposait invariablement d’un système de classification. Dans ma lointaine jeunesse, il s’agissait d’un système de fiches, basé sur des chiffres. Aujourd’hui encore, chaque livre de la bibliothèque porte un numéro de catalogue collé au dos.
Lorsqu’Internet a vu le jour, Jerry Yang et David Filo ont pensé que quelqu’un devait s’atteler à faire la même chose avec les sites web et ils ont créé (gloire à eux) l’annuaire Yahoo. Il s’agissait d’une liste de sites web établie manuellement, avec un petit résumé du contenu de chaque site, lequel était classé dans une catégorie hiérarchique. Selon les critères actuels, ce n’était pas très sophistiqué, mais à ces temps immémoriaux, Yahoo était l’entreprise en ligne la plus précieuse au monde. Deux variantes populaires du modèle sont Looksmart, utilisé par Microsoft, et l’Open Directory Project, qui est une variante libre pouvant être utilisée par n’importe quel moteur de recherche (y compris Google par la suite).
En concurrence avec cette idée de classification des sites web, le concept de « recherche en texte intégral », mené par AltaVista et une myriade d’autres sociétés (y compris un effort courageux de Yahoo), a finalement été remporté par Google en Occident, Baidu en Chine et Yandex en Russie. La recherche plein texte était plus prometteuse, à condition que tout se mette en place. La curation, c’est-à-dire la mise en avant manuelle des sites web était trop lente. Tout le contenu d’un site devait être expliqué en quelques phrases, un peu comme le système de catalogage de la bibliothèque locale. La recherche en texte intégral, en revanche, ne nécessitait aucune intervention manuelle et chaque page pouvait constituer une entité distincte dans l’index qui s’en trouvait énormément amplifié au passage.
Les bases de connaissances sont, dans une certaine mesure, un retour à l’ancienne façon de faire les choses. Nous reviendrons sur cet argument plus tard, mais tout d’abord, explorons les différences entre l’indexation basée sur un catalogue ou un répertoire et l’indexation basée sur le texte. Puis plongeons-nous dans certains des concepts qui sous-tendent l’indexation basée sur le texte.
Les experts en référencement qui manquent de temps et qui connaissent déjà la recherche textuelle ont le droit de passer à la section suivante.
Recherche dans un répertoire vs recherche dans le texte

Les deux approches de l’indexation du web présentaient des avantages. Et elles en ont encore. En fin de compte, l’approche basée sur le texte intégral l’a finalement emporté… jusqu’à nouvel ordre. Cependant, avec la croissance continue du web, la mission de Google, qui consiste à « organiser l’information mondiale », s’est heurtée à de nouveaux obstacles. Étant donné qu’il y a beaucoup plus de pages sur Internet à propos de n’importe quel sujet que quiconque puisse lire, quel est l’intérêt pour Google d’essayer de collecter continuellement l’information et de l’ordonner, si personne ne regarde jamais au-delà de la première page de résultats ? Même les ressources de Google sont limitées, et quand bien même ce ne serait pas le cas, les ressources de la planète sont limitées. Vous serez peut-être surpris d’apprendre qu’on estime que l’énergie nécessaire pour soutenir les recherches de Google équivaut à l’alimentation de 200 000 foyers. Statista indique que Google a consommé quatre fois plus d’énergie en 2022 qu’en 2015. Google pourrait encore maintenir cette consommation exponentielle en achetant de l’énergie renouvelable, mais jusqu’à un certain point seulement. La loi de Moore, qui suggérait que les micropuces continueraient à devenir de plus en plus rapides, a atteint un obstacle à la fois physique et économique. Les ordinateurs quantiques combleront peut-être ce vide, mais pour l’instant, force est de constater que tout moteur de recherche doit faire des compromis.
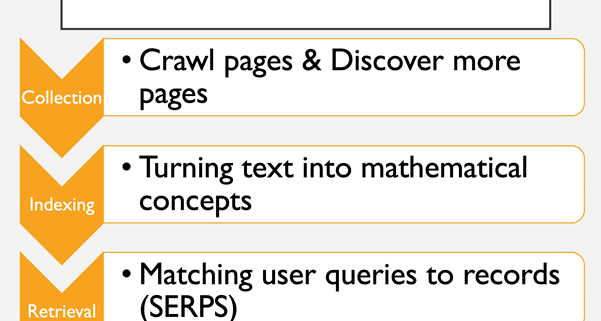
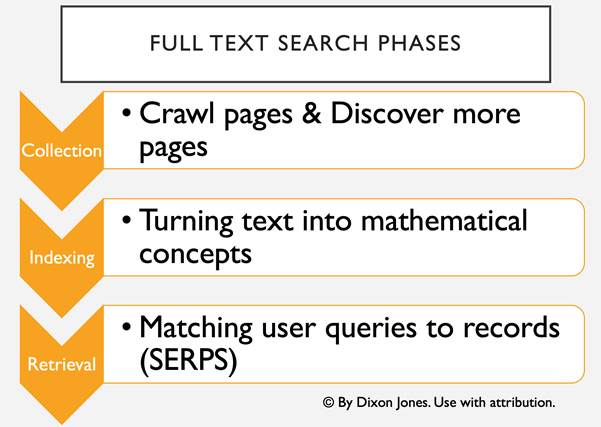
Jusqu’à cet inattendu point de crise, la recherche en texte intégral avait tué la recherche par curation manuelle. Pour obtenir des résultats de qualité à destination des utilisateurs, les moteurs de recherche devaient transformer les chaînes de texte (qui sont notoirement difficiles à analyser par les machines) en concepts numériques et mathématiques, qui peuvent ensuite être facilement classés ou notés, prêts pour le moment où les utilisateurs auraient besoin de réponses à leurs requêtes
Phase d’exploration et de découverte
La plupart des moteurs de recherche découvrent le contenu en l’explorant, bien que l’exploration traditionnelle soit loin d’être la seule manière pour les moteurs de recherche d’ingérer du contenu. Selon Incapsula (aujourd’hui Impervia), la majeure partie du trafic web provient des robots. Il ne s’agit pas seulement de Google et de Bing. Les robots distribués par Majestic (dont j’ai été directeur), un moteur de recherche spécialisé dans l’analyse des liens entre les pages web, scannent plus vite que Bing. J’en ai discuté un jour avec un ami de Microsoft qui m’a dit que l’un des objectifs de Microsoft était de réduire au maximum le besoin de crawler. Je ne sais pas si c’est vrai, mais il est certain qu’à l’heure actuelle, l’exploration du web est le principal moyen utilisé par les moteurs de recherche pour ingérer du texte. C’est également la principale façon dont ils découvrent de nouvelles URL et de nouveaux contenus pour alimenter leurs robots insatiables, car l’exploration d’une page révèle des liens vers de nouvelles pages, qui peuvent ensuite être placées dans un système de file d’attente pour l’exploration suivante.
La découverte de nouveaux contenus se fait également sous de nombreuses autres formes. Les plans de site sont très utiles à Google et les propriétaires de sites web peuvent facilement soumettre des plans directement à Google par l’intermédiaire de la « Webmaster Search Console » (console de recherche pour les webmasters). Ils peuvent également faire des économies en consultant les flux d’actualités ou les flux RSS qui s’actualisent au fur et à mesure que le contenu du site web est mis à jour.
L’exploration à grande échelle a été relativement efficace pendant de nombreuses années. Le robot pouvait simplement saisir le code HTML de la page ainsi que d’autres métadonnées et traiter le texte de la page ultérieurement. Cependant, la technologie ne s’arrête jamais et les premiers cadres, puis les iFrames, puis les CSS et enfin le Javascript ont commencé à ajouter de la complexité à ce processus. Javascript, en particulier, crée une énorme surcharge de travail pour les moteurs de recherche. Or le contenu fourni par Javascript est rendu du côté client. En d’autres termes, votre PC, votre ordinateur portable ou votre téléphone utilise une partie de son processeur pour faire apparaître la page web telle qu’elle est. Qu’un robot d’indexation lise toutes les pages de l’internet est une chose. Pour qu’il puisse les parcourir ET comprendre le Javascript en même temps, il faudrait que les robots d’exploration ralentissent à un tel rythme que l’exploration ne pourrait pas se faire à grande échelle. Google a donc introduit une quatrième étape dans le processus d’indexation.
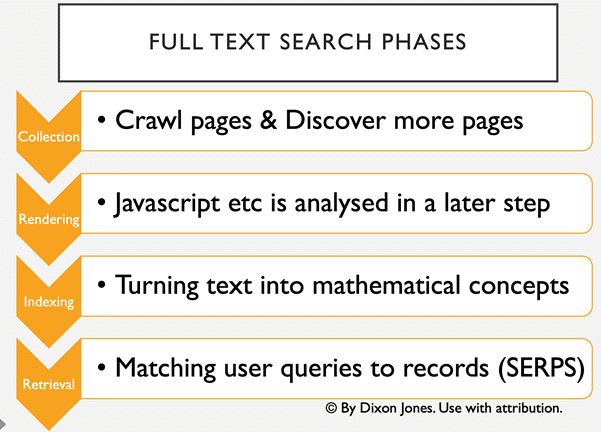
Le défi du Javascript
Google semble actuellement être le chef de file en matière d’analyse de Javascript et s’est certainement amélioré de manière significative au cours des dernières années. Néanmoins, la charge de calcul requise par le Javascript est immense. Le traitement a parfois lieu plusieurs semaines après l’exploration initiale et des compromis importants doivent être faits. Martin Splitt, de Google, présente plusieurs excellentes vidéos concernant ce véritable challenge.
Transformer un texte en concepts mathématiques
Nous abordons maintenant le cœur de la recherche en texte intégral. Les référenceurs ont tendance à s’attarder sur la partie indexation de la recherche ou sur la partie récupération de la recherche, appelée pages de résultats des moteurs de recherche (SERP, en abrégé). Je pense qu’ils agissent ainsi parce qu’il s’agit des parties apparentes de la recherche, la partie émergée de l’iceberg en quelque sorte. Ainsi ils peuvent savoir si leurs pages ont été explorées ou si elles apparaissent. Ce qu’ils ont tendance à ignorer, c’est la boîte noire qui se trouve au milieu. Il s’agit du moment où un moteur de recherche prend tous ces milliards de mots et les place dans un index de manière à permettre une recherche instantanée. En même temps, il est capable de mélanger des résultats textuels avec des vidéos, des images et d’autres types de données dans un processus connu sous le nom de « recherche universelle ». C’est là le cœur du problème et, bien que ce guide n’ait pas pour ambition de couvrir l’ensemble de ce sujet complexe, nous aborderons un certain nombre d’algorithmes utilisés par les moteurs de recherche. J’espère que ces explications algorithmiques parfois complexes, mais surtout itératifs, intéresseront le spécialiste du marketing qui sommeille en vous et ne mettront pas trop à l’épreuve vos compétences en mathématiques.
Si vous souhaitez reprendre cette explication sous forme de vidéo, je vous recommande vivement celleréalisée par Peter Norvig de Google en 2011 : https://www.youtube.com/watch?v=yvDCzhbjYWs
Sac de mots continu (COBW) et nGrams
Il s’agit d’un excellent algorithme pour commencer, car il est facile à visualiser. Imaginez un ordinateur qui lit des mots à toute vitesse. Il lit un mot sur une page, puis le suivant, puis le suivant. Chaque mot lu fait l’objet d’une réflexion initiale qui appelle une décision.
Décision : ce mot est-il potentiellement important ?
Il répond à la question en éliminant tous les mots très courants tels que « un », « le », « la »…. Pour ce faire, il se réfère à une liste (établie) de mots vides (stop words).
Décision : s’agit-il de la bonne variante ?
En même temps qu’il décide de supprimer un mot, il peut le modifier légèrement, en supprimant le « s » de « fers à cheval » ou en associant des mots en majuscules à des variantes sans majuscules. En bref, il regroupe différentes variantes en une seule forme. Nous y reviendrons lorsque nous parlerons des entités, car avouez qu’il n’y a pas beaucoup de différence entre « ordures », « déchets » et « détritus ».
Ensuite, le système compte simplement les mots. Chaque fois qu’il voit le mot « fer à cheval », il ajoute 1 au nombre total de fois où il a vu le mot « fer à cheval » sur l’internet et ajoute 1 au nombre de fois où il l’a vu sur la page qu’il est en train de regarder. Tiens, au fait, techniquement, les experts en recherche d’informations appellent les pages des « documents », principalement pour des raisons historiques antérieures à l’avènement d’Internet, mais peut-être aussi pour que les mortels que nous sommes se sentent inférieurs !
Quand le moteur de recherche voit qu’un internaute cherche le mot « fer à cheval », il est capable de trouver la page où le mot est le plus souvent mentionné. C’est une très mauvaise façon de construire un moteur de recherche, car une page qui ne fait que spammer le mot « fer à cheval » arriverait en tête, au lieu d’une page qui parle réellement de fers à cheval, mais nous aborderons ce type de spam lorsque nous parlerons du PageRank et d’autres outils de classement. Il s’agit toutefois d’un excellent moyen de stocker efficacement tous les mots présents sur Internet. Que le mot soit utilisé une fois ou un million de fois, la quantité de stockage nécessaire est à peu près la même et n’augmente qu’en fonction du nombre de pages présentes en ligne. Tiens, au fait, les experts en recherche d’information appellent souvent Internet le « corpus » de « documents »… en partie pour des raisons historiques, mais je commence à penser qu’ils le font par intellectualisme passif-agressif. Jugez-en par vous-même).
Ce système devient beaucoup plus utile lorsque le crawler commence à compter les mots qui se trouvent les uns à côté des autres, appelés n-grammes. Le robot peut alors compter le nombre de phrases de plusieurs mots, après avoir éliminé les mots vides et choisit la variante dominante de chaque mot. En 2006, Google est même allé jusqu’à publier un ensemble de données de n-grammes pour 13 millions de mots, qui est présenté dans la conférence de Peter Norvig et reste disponible au téléchargement.
Nombre de phrases : 95,119,665,584
– Nombre d’unigrammes : 13,588,391
– Nombre de bigrammes : 314,843,401
– Nombre de trigrammes : 977,069,902
– Nombre de quatre grammes : 1,313,818,354
– Nombre de cinq grammes : 1,176,470,663
Aujourd’hui, nous pouvons tirer d’énormes quantités d’informations de ces données. En anglais, Google sait que l’expression « le renard rapide » (quick fox) est beaucoup plus courante que « le renard rusé » (smart fox) sur internet. Il ne sait pas pourquoi, mais il n’a pas besoin de le savoir. Il lui suffit de renvoyer des pages pertinentes pour « le renard rapide » lorsqu’une personne effectue une recherche à ce sujet.
Note à l’attention des francophones qui n’ont rien compris au paragraphe précédent:
“The quick brown fox jumps over the lazy dog.” est une phrase célèbre dans le monde anglophone car elle contient toutes les lettres de l’alphabet. Elle est utilisée par les entreprises du monde entier pour présenter des types de polices de caractères dans leur intégralité. C’est un exemple de pangramme, une phrase qui utilise tout l’alphabet. Un équivalent français pourrait être : « Portez ce vieux whisky au juge blond qui fume ».
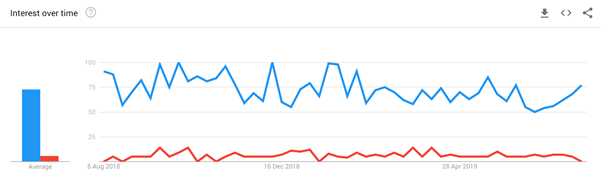
Figure 1 : Vous pouvez vérifier l’utilisation des recherches. Le graph bleu correspond au « renard rapide » et le rouge au « renard rusé ».
Un moteur de recherche peut examiner le nombre de fois où les mots recherchés – individuellement et collectivement – apparaissent sur une page. Mis à part le spamming, il existe une myriade de façons d’évaluer chaque document pour cette phrase.
Les vecteurs
Une autre révélation s’impose. Après avoir constaté que l’expression « le renard rapide » est beaucoup plus populaire sur Internet que « le renard rusé », nous pouvons également en déduire qu’en anglais, le mot « rapide » est sémantiquement plus proche du mot « renard » que le mot « intelligent ». Il existe de nombreux algorithmes, tels que « Word2Vec », qui utilisent ce type d’intuition pour mettre en correspondance des mots sur la base de leur « proximité ». Les mots « roi et reine » sont proches, tandis que les mots « roi et renard » sont très éloignés l’un de l’autre. Pour en savoir plus, consultez « Vector Space Models » (modèles d’espace vectoriel).
À partir des balises sémantiques que vous incluez dans les pages, Google et les autres moteurs de recherche peuvent raccourcir les algorithmes dont ils ont besoin pour transformer les mots en concepts. Vous aidez ainsi les machines à lire, assimiler et comprendre vos contenus. Cela dit, il serait assez facile d’abuser de ce système. Le graphe de connaissances n’augmente les informations qu’il possède déjà que lorsqu’il est certain que les recommandations du balisage sémantique sont valides. Si les moteurs de recherche se trompent, le balisage sémantique sera un peu plus efficace que le bourrage de mots-clés comme au bon vieux temps du référencement.
Pour ce faire, les moteurs de recherche doivent-ils encore faire confiance aux humains ! En effet, le Knowledge Graph a commencé par un ensemble de données sélectionnées… par l’homme.
Des sources de confiance : gloire à l’annuaire !
Nous avons commencé notre voyage dans le temps de la recherche en discutant de la façon dont les annuaires web gérés par des humains, comme Yahoo Directory et l’Open Directory Project, ont été surpassés par la recherche en texte intégral. Le passage à la recherche sémantique est un mélange des deux concepts. Au fond, la base de connaissances de Google extrapole des idées à partir de pages web et enrichit sa base de données. Toutefois, l’ensemble de données initiales est formé à l’aide d’ensembles de « sources fiables », dont le plus visible est la fondation Wikipédia. Wikipédia est gérée par des humains et si un élément est répertorié dans Wikipédia, il est presque toujours répertorié en tant qu’entité dans le Knowledge Graph de Google.
Cela signifie que toute l’intégrité de l’approche de la recherche basée sur les entités dépend de l’intégrité et de l’authenticité des bénévoles (généralement non rémunérés) qui gèrent le contenu de Wikipédia. Cela pose quelques menus problèmes d’échelle et d’éthique qui sont examinés par l’auteur ici.
Ainsi, à bien des égards, le graphe de connaissances c’est l’ancien annuaire web qui boucle la boucle. Les premiers annuaires utilisaient une structure arborescente un peu rigide, tandis que le graphe de connaissances est évidemment beaucoup plus fluide. En outre, la plus petite unité d’une structure de répertoire était en réalité une page web (ou plus souvent un site web), tandis que la plus petite unité d’un graphe de connaissances est une entité, qui peut apparaître dans de nombreuses pages, mais les deux idées découlent en fait des décisions initiales prises par les humains.
Cela nous amène à la question de savoir ce que Google considère comme une entité et ce qu’il ne considère pas comme telle. Il est clair qu’il est important de savoir cela si nous voulons commencer à « optimiser » le référencement sémantique.
| Page précédente | Guide du SEO sémantique | Page suivante |