
Techniquement parlant, le graphique de connaissance de Google alias le fameux « Google Knowledge Graph » est une base de connaissances contenant des informations acquises à partir de plusieurs sources. Mais c’est aussi la mise en relations de ces informations entre elles. Le but de ce graph’ est d’améliorer les résultats de recherche. Ce concept a été introduit en 2012 comme un moyen de fournir des informations toujours plus pertinentes, précises et utiles sur la base des recherches effectuées par les utilisateurs sur le web par l’intermédiaire des moteurs de recherche. Le graphe de connaissances présente aux utilisateurs les informations de plusieurs manières, notamment par le biais d’une infobox ou d’un panneau de connaissances généralement placé à côté des résultats.
Le panneau de connaissances présente une grande variété d’informations concernant un sujet ou une entité. Par exemple, lorsqu’un utilisateur tape le nom d’un musicien célèbre, le panneau de connaissances affiche des détails tels que le nom complet du musicien, des images, la liste de ses chansons, ses morceaux récents, ses événements à venir, ses partenaires et d’autres détails. Le graphe de connaissances permet de créer une base de données en utilisant les données disponibles sur l’entité afin de créer des relations significatives.
Les graphes de connaissances améliorent considérablement l’expérience de l’utilisateur, qui dispose d’un large éventail d’informations sur un sujet, ce qui lui évite d’avoir à multiplier les requêtes pour parvenir à ses fins. Cela permet de réduire le nombre de clics et le temps nécessaire pour atteindre un contenu pertinent en rapport avec sa recherche.
La base de connaissances est créée en établissant des relations entre diverses entités. Dans ce cas, les entités font référence à des concepts ou à des choses que l’on peut distinguer, notamment des personnes, des lieux, des sentiments, des couleurs et des organisations. L’apprentissage automatique et d’autres algorithmes sont déployés dans les graphes de connaissances afin de fournir les informations les plus pertinentes et les plus utiles aux internautes. L’interconnexion de données provenant de millions de sources et l’utilisation de concepts d’apprentissage automatique permettent aux graphes de connaissances de constituer une vaste base de savoirs contenant des informations utiles et précises sur les entités. Lors de la recherche d’un contenu sur le web, les graphes utilisent des méthodes de recherche sémantique pour renvoyer les informations les plus pertinentes. Ils sont conçus de manière à pouvoir analyser la relation entre les mots-clés et les phrases, afin de mieux comprendre ce qui intéresse l’utilisateur, ou de comprendre le contexte de la recherche de manière à renvoyer des résultats adéquats.
Les marges sont utilisées pour relier les différentes entités et fournir une description de la nature de leurs relations. Grâce au graphe de connaissances, Google est en mesure de présenter aux internautes davantage d’informations pertinentes pour une recherche spécifique et d’augmenter le trafic relevant du SEO. De plus, le graphe de connaissances de Google permet d’améliorer les recherches vocales en identifiant les entités comprises dans une phrase parlée. Une entreprise peut bénéficier des graphes de connaissances car ils fournissent normalement des informations détaillées la concernant. Par exemple les utilisateurs trouvent des informations sur les événements futurs planifiés par une entreprise, ce qui est bénéfique pour cette dernière.
Petite étude de cas d’un graphe de connaissance
Prenons, par exemple, la phrase suivante :
« Queen est un groupe de rock »
C’est un exemple de « triplet sémantique »
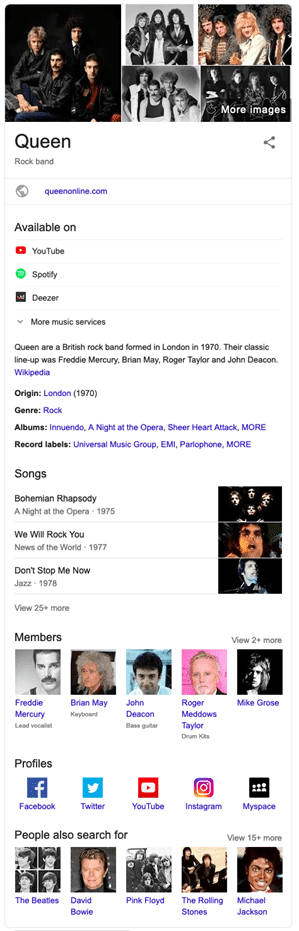
Voici quelques éléments que le graphe de connaissances pourrait mémoriser pour « Queen, le groupe de rock » :
- Freddy Mercury (est membre de) Queen, (qui est un) groupe de rock,
- Bohemian Rhapsody (est une) chanson (écrite par) Queen, (qui est un) groupe de rock
- Innuendo (est un) album (écrit par) Queen, (qui est un) groupe de rock
- Live Aid (est un) concert (avec) Queen, (qui est un) groupe.
Les éléments en gras sont tous des entités. Ils sont tous liés par une relation (indiquée entre parenthèses). « Personne », « groupe » et « concert » sont en réalité des classifications de choses ou des @types de choses, plutôt que des choses à part entière… c’est-à-dire que de nombreuses personnes peuvent être classées comme une entité « personne ». Queen dans ce cas de figure est classé comme un groupe. Dans un autre contexte, Queen peut aussi bien être classé comme (disons) un monarque. Voici quelques types de classificateurs @ courants :
- Personne
- Lieu
- Date
- Organisation
- Étude
- Recette
- Événement
En établissant la donnée Queen (un groupe) avec ces lignes de relations vers d’autres entités, le tableau qui est généré agit comme un ensemble de données semi-structurées concernant l’entité Queen. Ainsi, lorsque vous tapez « Queen, groupe » dans Google, vous obtenez non seulement le site web officiel du groupe mais également une « boîte de connaissances » qui n’est autre que l’ensemble de ces relations présentées de manière attrayante : leur chaîne YouTube, leur chaîne Spotify, leurs albums, leurs membres, la discographie et bien plus encore.
Remarquez l’importance de Wikipédia dans une grande partie du Knowledge Panel. Google a indiqué dans ses présentations qu’il utilisait les données de la fondation Wikipedia comme principal ensemble de données pour l’entraînement de ses propres systèmes lors de la construction du graphe de connaissances. IMDb (Internet Média Database, une base de donnée sur le cinéma, la télévision et les jeux vidéos) semble également avoir été mis à contribution pour cet exemple.
Le concept de triplet sémantique
Dans le domaine de la recherche sémantique, un « triplet » est une relation entre deux entités ou deux @types d’entités. (Le signe @ que nous continuons à utiliser prendra tout son sens un peu plus loin).
Continuons notre présentation avec la même entité, en prenant l’exemple suivant : « Freddy Mercury (est membre de) Queen, (qui est) un groupe de rock ». Cet exemple est en fait plus compliqué qu’un « triplet ». En réalité cette assertion contient TROIS triplets :
- Freddy Mercury (est membre de) Queen
- Queen, (est un) groupe de rock
- Nous pouvons donc déduire un troisième triplé de cela : « Freddy Mercury » (est dans un) « groupe de rock«
Les triplets constituent le cœur du graphe des connaissances. Bien qu’il soit intéressant de constater ici que des données incomplètes peuvent créer des erreurs. Il serait plus correct d’avoir dit Freddie Mercury « était » dans un groupe de rock. Sans la date de sa mort comme autre triplet, la déduction est en fait fausse. Cela est dû au fait que les données d’entrée, disant que Freddie EST un membre de Queen, étaient également fausses.
Comment le graphe de connaissance a changé la recherche
Maintenant que Google a compris que Queen est une entité, il peut aller beaucoup plus loin, en enrichissant les traditionnels résultats de recherche. Maintenant qu’il a lié l’entité à sa chaîne YouTube officielle il peut facilement afficher quelques vidéos dans les résultats, par exemple. Un petit clip en guise de supplément, ça ne peut pas faire de mal.
Remarquez que dans la boîte de connaissances correspondant à Queen, l’une des premières entités listées est « queenonline.com ». Le site web officiel est en soi une entité liée à Queen, le groupe. Il n’est donc pas surprenant que Google place également ce site web au premier rang des résultats organiques traditionnels.
Vecteurs
À partir de cet exemple de boîte de connaissances dédiée à Queen, vous pouvez probablement voir que Google est susceptible de considérer que John Deacon et Freddie Mercury sont « sémantiquement proches » l’un de l’autre. De même, Google pense que les Beatles et Pink Floyd sont probablement des groupes sémantiquement proches. Il s’agit là d’un concept extrêmement important à comprendre pour les référenceurs. Si vous voulez écrire sur Queen, le groupe, vous avez évidemment intérêt à écrire aussi sur John Deacon et Freddie Mercury. Mais vous devriez aussi parler de Londres dans les années 1970, des autres groupes anglais de l’époque, et des techniques vidéo étonnantes utilisées dans Bohemian Rhapsody. Bien sûr, cela ne vous aidera pas à mieux vous classer pour le terme « Queen, groupe », car cette entité est déjà entièrement définie. Or, sauf erreur de notre part, vous ne possédez pas le site web officiel de Queen (à moins que l’on se trompe, auquel cas auriez-vous la gentillesse de faire un lien vers cet article ?). Cependant, vous pouvez toujours générer du trafic organique lié à Queen, le groupe. C’est ce que nous décrivons dans la section « Optimiser pour les contours ».
Si vous voulez être un bon référenceur, vous devrez en savoir plus sur la façon dont les algorithmes fonctionnent et comment ils peuvent à partir du texte, établir des hiérarchies et des données de manière à fournir, à nous, les humains, des résultats de recherche utiles.
Vous pouvez analyser sémantiquement n’importe quelle page web, comme le fait Google, gratuitement sur Inlinks.com.
| Page précédente | Guide du SEO sémantique | Page suivante |
Laisser un commentaire
Rejoindre la discussion?N’hésitez pas à contribuer !